EXPLAIN(실행계획)
EXPLAIN 키워드를 사용하여 실행계획 정보 출력
mysql> explain select * from employees where emp_no = '10001';
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
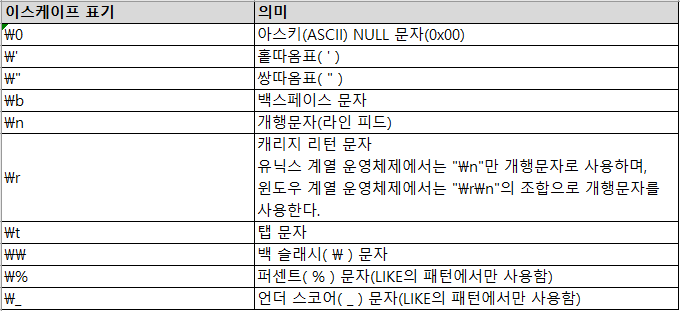
| id | select 문장은 하나인데 여러개의 테이블이 조인되는 경우에는 ID값이 증가하지 않고 같은 ID를 부여 |
| table | 참조하는 테이블 항목 |
| select_type | 각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 컬럼 |
| type | 각 테이블의 접근 방식(Access type) |
| possible_keys | 인덱스 후보 목록(무시 해도 됌) |
| key | 실제 사용할 인덱스 |
| key_len | 다중 컬럼으로 구성된 인덱스에서 몇개의 컬럼까지 사용했는지 알 수 있는 정보(인덱스 길이) |
| ref | 해당 테이블에 엑세스하는 접근 방식 |
| rows | 예측 레코드 건수 |
| filtered | 어느 정도의 비율로 데이터를 제거했는지 의미하는 항목 |
| extra | SQL문을 어떻게 수행할 것인지에 대한 추가 정보 |
id
id는 SELECT에 붙은 번호이며 실행 순서
id가 작을수록 먼저 수행, id가 같은 값이라면 두 개 테이블이 조인 되었다고 볼 수 있음
MySQL은 조인을 하나의 단위로 실행하기 때문에 id로 쿼리의 실행 단위를 식별함
SQL에 서브쿼리나 UNION이 없다면 SELECT는 하나 이므로 모든 행에 대해 1이란 값이 부여되지만 이외의 경우에는 원 구문에서 순서에 따라 각 SELECT 구문들에 순차적으로 번호가 부여됨
select_type
SQL문을 구성하는 SELECT 문의 유형을 출력하는 항목
FROM에 위치하는지, 서브쿼리인지, UNION절로 묶인 SELECT 인지를 나타냄
| SIMPLE | Union이나 Sub Query가 없는 단순한 SELECT문 |
| PRIMARY | 서브쿼리가 포함된 SQL문의 메인쿼리, UNION을 사용 할 경우 첫 번째 쿼리 |
| UNION | Union (All) 쿼리에서 Primary를 제외한 나머지 SELECT문 |
| DEPENDENT_UNION | UNION과 동일하나 바깥 쿼리에 의존성을 가진 Union의 SELECT문 |
| UNION_RESULT | Union 쿼리의 결과물 UNION ALL이 아닌 UNION 구문으로 SELECT절을 결합했을 때 출력 |
| SUBQUERY | 독립적으로 수행되는 서브쿼리 가장 밖에 있는 SELECT문의 Sub Query or Sub Query를 구성하는 여러 쿼리 중 첫번째 구문 즉, 스칼라 서브쿼리와 WHERE 절의 중첩 서브쿼리일 때 표시 |
| DEPENDENT_SUBQUERY | UNION (ALL)을 사용하는 서브쿼리가 메인테이블에 영향을 받는 경우 SUBQUERY와 동일하난 바깥 쿼리에 의존성을 가진 Sub Qeury의 SELECT문 |
| DERIVED | 서브쿼리가 재사용되지 못할 때 출력되는 유형 SELECT로 추출된 테이블(FROM 절에서의 Sub Query 또는 Inline View) FROM절의 별도 임시 테이블인 인랴인 뷰를 의미 |
| UNCACHEABLE_SUBQEURY | SUBQUERY와 동일하지만 공급되는 모든 값에 대해 Sub Query를 재처리 바깥 쿼리에서 공급되는 값이 동일하더라도 Cache된 결과를 사용할 수 없음 - 해당 서브쿼리 안에 사용자 정의 함수나 사용자 변수가 포함되거나 RAND(), UUID() 함수 등을 사용하여 매번 조회 시 결과가 달라지는 경우에 해당 |
| UNCACHEABLE_UNION | UNION과 동일하지만 공급되는 모든 값에 대하여 UNION 쿼리를 재처리 |
| METERIALIZED | IN절 구문에 연결된 서브쿼리가 임시 테이블을 생성한 뒤, 조인이나 가공 작업을 수행할 때 출력되는 유형 IN절의 서브쿼리를 임시 테이블로 만들어서 조인 작업을 수행 |
table
행이 어떤 테이블에 접근하는 지를 나타냄
테이블을 사용하지 않는 경우 table이 null로 표시되고 서브쿼리인 경우에는 <subquery#> 이 출력
table 컬럼에 <derived>, <union> 과 같이 "<>" 가 표시되는 경우 임시테이블을 의미함.
"<>"안에 표시되는 숫자는 SELECT문의 id를 나타냄
type
데이터 접근 방식을 표시하는 필드
상위에 위치한 type일 수록 빠른 방식
| system | 테이블에 단 한개의 데이터만 있는 경우 |
| const | PK or Unique Key를 이용하여 조회하는 경우 |
| eq_ref | 조인 키가 inner(driven) 테이블의 기본 키나 고유 인덱스를 사용하여 단 1건의 데이터를 조회하는 경우 |
| ref | 조인을 할 때 PK나 Unique Key가 아닌 Key로 매칭하는 경우 조인할 때 driven 테이블의 데이터 접근 범위가 2개 이상인 경우, driving-dirven 관계가 1:M |
| ref_or_null | ref와 같지만 null이 추가되어 검색되는 경우 IS NULL 구문에 대해 인덱스를 활용하도록 최적화된 방식 - IS NULL 구문을 수행 시 인덱스 활용할 때 표시 - 인덱스 접근 시 맨 앞에 저장되어 있는 NULL의 엔트리를 검색 - 검색할 NULL 데이터가 적다면 ref_or_null 방식을 활용했을 때 효율적 |
| index_merge | 두 개의 인덱스가 병합되어 검색 |
| unique_subquery | IN 서브쿼리 접근에서 기본 키 또는 고유 키를 사용. |
| index_subquery | IN 서브쿼리에서 unique_subquery와 거의 비슷하지만 고유한 인덱스를 사용하지 않음 |
| range | 특정 범위 내에서 인덱스를 사용하여 범위 비교할 때 사용 데이터가 방대하지 않다면 단순 SELECT 에서는 나쁘지 않음 |
| index | index full scan, 인덱스를 처음부터 끝까지 찾아서 검색하는 경우 |
| all | table full scan, 테이블을 처음부터 끝까지 검색하는 경우 검색하려는 데이터가 전체 데이터의 20%정도 이상일 때는 ALL 성능이 인덱스 범위 검색보다 성능이 좋을 수 있음 |
- ALL, index 두 가지는 테이블 또는 특정 인덱스가 전체 행에 접근하기 때문에 테이블 크기가 크면 효율이 떨어짐
- ref_or_null 의 경우 NULL이 들어 있는 행은 인덱스의 맨 앞에 모아서 저장하지만 그 건수가 많으면 MySQL 서버의 작업량이 커짐
- 즉 ALL 이외의 접근 방식은 모두 인덱스를 사용하는데 해당 쿼리로 사용할 수 있는 적절한 인덱스가 없다는 의미 일 수도 있음
possible_keys
사용 가능한 인덱스 목록
쿼리에서 사용된 컬럼과 비교 연산자를 토대로 어떤 인덱스를 사용할 수 있는지를 표시
실제 사용한 인덱스가 아닌 사용할 수 있는 후보 인덱스 목록
key
사용된 PK 또는 Index
key가 NULL이면 인덱스를 사용할 수 없는 쿼리
key_len
key_len 필드는 선택된 인덱스의 길이를 의미
ref
테이블 조인시 어떤 조건으로 해당 테이블에 엑세스 되었는지 나타냄
키 컬럼에 나와있는 인덱스에서 값을 찾기 위해 선행 테이블의 어떤 컬럼이 사용되었는지 나타냄
rows
원하는 행을 찾기 위해 접근하는 데이터의 모든 행의 예측값
EXPLAIN ANALYZE를 제외하곤 EXPLAIN은 MySQL 통계 정보를 토대로 예측
SQL문의 최종 결과 건 수와 비교해 rows 차이가 많이 나는 경우 튜닝 대상이 됨
Filtered
필터 조건에 따라 제거된 비율(%)
필터가 제대로 동작하지 않으면 테이블 등을 ANALYZE 해서 분석을 해야 함
Extra
옵티마이저가 SQL문을 어떻게 해석하여 수행할 것인지에 대한 추가정보
| Using where | WHERE 절의 필터 조건을 사용 |
| Using index | 인덱스만 읽고 처리(covering index OR index only scan) |
| Distinct | 중복이 제거되어 유일한 값을 찾음(중복 제거가 포함되는 distinct 키워드, union 구문 사용 시) |
| Using index for group-by | Group by가 포함되어 있는 쿼리를 인덱스만 읽고 처리 |
| Using filesort | 정렬이 필요한 데이터를 메모리에 올리고 작업을 수행 Order by를 인덱스로 해결하지 못하고 filesort(MySQL의 quick sort)로 정렬 |
| Using temporary | 임시 테이블 |
| Using where with pushed | distinct, group by, order by 구문이 포함된 경우 표시, pushdown 최적화가 일어난 것을 표시 |
| Using index condition | index condition pushdown(ICP) 최적화 |
| Using MRR | 멀티 레인지 리드(MRR) 최적화 |
| Using join buffer(Block Nested Loop) | 조인에 적절한 인덱스가 없어 중간 데이터 결과를 저장하는 조인 버퍼 사용 |
| Using join buffer(Batched Key Access) | Batched Key Access(BKAJ) 알고리즘을 위한 조인 버퍼를 사용했음을 표시 |
| Not exists | 하나의 일치하는 행을 찾으면 추가로 행을 더 검색하지 않아도 될 때 출력하는 유형 |
| Using union Using intersect Using sort_union |
인덱스가 병합되어 실행되는 경우 Using union : 인덱스들을 합집합처럼 결합, OR구문 Using intersect : 인덱스들을 교집합처럼 추출하는 방식, AND구문 Using sort_union : Using union과 유사하지만, OR 구문이 동등 조건이 아닐 때 확인할 수 있는 정보 |
EXPLAIN ANALYZE
실제 실행된 소요 시간, 비용을 측정하여 실행 계획 정보를 출력하고 싶다면 ANALYZE 키워드를 사용해서 분석
(EXPLAIN 키워드만 사용되는 경우 통계정보를 활용한 예측된 실행계획)
[사용방법]
1) EXPLAIN ANALYZE 키워드를 사용
2) ANALYZE "테이블명" => EXPLAIN
EXPLAIN ANALYZE
select *
from employees
where emp_no >=10002;
-> Filter: (employees.emp_no >= 10002) (cost=30011 rows=149601) (actual time=1.15..270 rows=300023 loops=1)
-> Index range scan on employees using PRIMARY over (10002 <= emp_no) (cost=30011 rows=149601) (actual time=1.11..251 rows=300023 loops=1)
EXPLAIN의 format Options
MySQL 8.0부터 EXPLAIN명령에 FORMAT 옵션을 사용해 실행 계획을 결과를 TABLE, JSON, TREE로 지정
Default EXPLAIN (Table view)
EXPLAIN
select *
from employees
where emp_no between '1' and '10000000'
;
id|select_type|table |partitions|type |possible_keys|key |key_len|ref|rows |filtered|Extra |
--+-----------+---------+----------+-----+-------------+-------+-------+---+------+--------+-----------+
1|SIMPLE |employees| |range|PRIMARY |PRIMARY|4 | |149601| 100.0|Using where|
EXPLAIN vertical view (쿼리 끝에 '\G' )
mysql> EXPLAIN
-> select *
-> from employees
-> where emp_no between 1 and 10000000\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 149601
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
EXPLAIN FROMAT = JSON
attached_condition은 어떤 조건이 사용되었는지 나오는 항목
EXPLAIN FORMAT = JSON
select *
from employees
where emp_no between '1' and '10000000';
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "29957.56"
},
"table": {
"table_name": "employees",
"access_type": "range",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no"
],
"key_length": "4",
"rows_examined_per_scan": 149601,
"rows_produced_per_join": 149601,
"filtered": "100.00",
"cost_info": {
"read_cost": "14997.46",
"eval_cost": "14960.10",
"prefix_cost": "29957.56",
"data_read_per_join": "19M"
},
"used_columns": [
"emp_no",
"birth_date",
"first_name",
"last_name",
"gender",
"hire_date"
],
"attached_condition": "(`employees`.`employees`.`emp_no` between '1' and '10000000')"
}
}
}
EXPLAIN FROMAT = TREE
EXPLAIN FORMAT = TREE
select *
from employees
where emp_no between '1' and '10000000';
-> Filter: (employees.emp_no between '1' and '10000000') (cost=29958 rows=149601)
-> Index range scan on employees using PRIMARY over (1 <= emp_no <= 10000000) (cost=29958 rows=149601)
실행계획 개선 방향
| select_type | DEPENDENT.* UNCACHEABLE.* |
SIMPLE PRIMARY DERIVED |
denpedent는 외부 테이블에 의존하게 되므로 부하 |
| type | index all |
system const eq_ref |
index full scan, table full scan 은 부하 |
| extra | Using filesort Using temporary |
Using index | 인덱스를 활용하여 filesort나 temporary 사용을 줄임 |
'MySQL > 튜닝' 카테고리의 다른 글
| MySQL DELETE & JOIN (0) | 2024.12.24 |
|---|---|
| MySQL LATERAL (0) | 2024.12.24 |
| MySQL WITH문에 상수, 바인드 변수, 사용자 정의 변수 "@" 사용 테스트 (0) | 2024.12.23 |
| MySQL : events_statements_summary_by_digest (0) | 2024.12.23 |
| MySQL Dictionary View 설명 (0) | 2024.12.23 |