ㅇㅇ
'Oracle > 서버튜닝' 카테고리의 다른 글
| Oracle Library Cache (0) | 2025.04.04 |
|---|---|
| Oracle I/O 대기 이벤트 (0) | 2025.04.03 |
| Oracle _optimizer_gather_stats_on_load (0) | 2025.04.02 |
| Oracle 19c 공간관리 및 Direct Path Load (0) | 2025.04.02 |
ㅇㅇ
| Oracle Library Cache (0) | 2025.04.04 |
|---|---|
| Oracle I/O 대기 이벤트 (0) | 2025.04.03 |
| Oracle _optimizer_gather_stats_on_load (0) | 2025.04.02 |
| Oracle 19c 공간관리 및 Direct Path Load (0) | 2025.04.02 |
dd
| Oracle Lock 튜닝 (0) | 2025.04.04 |
|---|---|
| Oracle I/O 대기 이벤트 (0) | 2025.04.03 |
| Oracle _optimizer_gather_stats_on_load (0) | 2025.04.02 |
| Oracle 19c 공간관리 및 Direct Path Load (0) | 2025.04.02 |
db file sequential read
db file sequential read 대기 이벤트는 Single Block I/O 수행 시에 발생하는 대기 이벤트.
한 번의 Single Block I/O가 발생할 때마다 한번의 db file sequential read 이벤트 대기가 발생한다.
Single Block I/O는 파일로부터 하나의 블록을 읽는 모든 작업들에서 발생 가능하며 일반적으로 인덱스 스캔 및 TABLE ACCESS BY ROWID 시에 발생한다.
Parameter
P1 : 파일# , P2 : 블록#, P3 : 블록 수 (항상 1)
Wait Time
I/O를 수행하기 위해 대기한 시간
일반적인 문제 상황 및 개선 방안
Index Clustering Factor
Index Clustering Factor(CF)는 인덱스 키 컬럼 기준으로 테이블의 데이터들이 얼마나 잘 정렬(군집)되어 있는지를 나타내는 수치이다. CF 값이 낮을수록 테이블의 데이터가 인덱스 순서와 유사하게 저장되어 있고, 높을수록 데이터가 인덱스 순서와 무작위로 흩어져 있음을 의미한다. CF는 메모리에 단 하나의 블록만을 담을 수 있는 공간이 있다고 가정하고, 인덱스 스캔 시에 테이블 블록을 몇 번 엑세스해야 하는지를 계산한 값이다.
즉, CF가 높을수록 db file sequential read 대기가 증가할 수 있는 가능성이 존재한다. CF값은 ANALYZE 명령문이나, DBMS_STATS 패키지를 이용해서 확인할 수 있다. 인덱스에 대해 통계정보를 생성하면 DBA_INDEXES.CLUSTERING_FACTOR에 CF의 값이 입력된다. CF 수치는 테이블의 블록 수에 가까울 수록 좋고, 로우 수에 가까울 수록 좋지 않다. 성능 문제의 원인이 CF인 경우, 테이블의 인덱스의 정렬순서와 동일한 순서로 재생성함으로써 해결할 수 있다. 하지만 테이블 재생성은 해당 테이블을 참조하는 다른 인덱스 성능에 영향을 미치므로 신중하게 고려한다.
SELECT t.owner
,i.index_name
,t.blocks
,i.num_rows
,i.clustering_factor
FROM dba_indexes i
,dba_tables t
WHERE i.table_name = t.table_name
AND i.table_owner = t.table_owner
AND i.index_name = :INDEX_NAME
;
Row Chaining, Row Migration
인덱스의 rowid를 통해서 테이블을 엑세스하는 경우, ROW CAHINING이나 ROW MIGRATION이 발생한 로우에 대해서는 추가적인 디스크 I/O가 발생하게 되면 db file sequential read 대기가 증가하게 됩니다. ANALYZE 명령을 이용해 통계정보를 생성하면 DBA_TABLES뷰의 CHAIN_CNT 컬럼에 CHAINING이나 MIGRATION이 발생한 로우수가 기록됩니다. 또한 아래와 같은 SQL문을 이용해서 현재 시스템상에서 발생하고 있는 ROW CHAINING나 ROW MIGRATION 발생 내역을 확인할 수 있다.
SELECT value
FROM v$sysstat
WHERE name = 'table fetch continued row'
;
SELECT a.sid, b.value
FROM v$session a, v$sesstat b, v$statname c
WHERE a.sid = b.sid
AND b.statistic# = C.statistic#
AND c.name ='table fetch coninued now')
db file scattered read
db file scattered read 대기 이벤트는 멀티 블록 I/O시 발생하는 대기 이벤트이다. FULL TABLE SCAN 및 INDEX FAST FULL SCAN을 수행하는 경우, 성능 향상을 위해 여러 개의 블록을 한번에 읽는 Multi Block I/O를 수행한다. Multi Block I/O를 한 번 수행할 때마다 Physical I/O가 끝나기를 기다리게 되며 db file scattered read 이벤트를 대기하게 된다.
Multi Block I/O는 DB_FILE_MULTIBLOCK_READ_COUNT 파라미터로 Multi block I/O를 수행할 때 한 번에 읽어올 데이터의 블록의 수를 지정한다. 하지만, 운영체제마다 Multi Block I/O의 최대 처리량에 제한이 있으므로 이 값을 너무 크게 설정하면 오히려 성능이 저하 될 수도 있다.
Parameter
P1 : 파일#, P2 : 시작 블록#, P3 : 블록 수
Wait Time
I/O를 수행하기 위해 대기한 시간
일반 문제상황 및 개선방법
Physical I/O 분류
Physical I/O는 Conventional Path I/O와 Direct Path I/O로 나뉜다.
Conventional Path I/O는 일반적으로 알고있는 버퍼 캐시를 경유하여 블록을 읽는 작업이다. Direct Path I/O는 데이터 파일에 있는 블록이 버퍼 캐시를 거치지 않고 PGA로 올리는 것이다. Direct Path I/O가 발생하면, I/O 작업 전에 체크 포인트가 발생하여 더티 버퍼(변경된 데이터 블록)를 데이터 파일에 기록한다. 이 작업을 통해 데이터 파일과 버퍼 캐시의 내용에 대해서 동기화 한 후 Direct Path I/O가 발생한다.
Index Full Scan vs. Index Fast Full Scan
인덱스 스캔에서 발생될 수 있는 성능문제는 넓은 범위 인덱스 스캔에 의한 I/O 발생량을 많이 일으키는 경우가 거의 대부분이다. 많은 양의 데이터를 읽어오면서 정렬이 필요 없는 경우라면 Single Block I/O가 발생되는 Index Full Scan이 아닌 Index Fast Full Scan을 사용하여 Multi Block I/O를 유도하는 것도 방법이다.
_FAST_FULL_SCAN_ENABLED=TRUE(DEFAULT=TRUE)
/*+ INDEX_FFS(Table_Alias INDEX_NAME) */
DB_FILE_MULTIBLOCK_READ_COUNT(MBRC) 설정
alter session set db_file_multiblock_read_count = 1000;
select /*+ full(a) */ count(*) from big_table a;
-- 아래의 예제는 10046 트레이스 파일로부터 발췌한 것
-- 시스템에서 허용할 수 있는 최대 MBRC는 128 블록
WAIT #1: nam='db file scattered read' ela=17946 p1=6 p2=56617 p3=128
WAIT #1: nam='db file scattered read' ela=21055 p1=6 p2=56745 p3=128
WAIT #1: nam='db file scattered read' ela=17628 p1=6 p2=56873 p3=128
WAIT #1: nam='db file scattered read' ela=29881 p1=6 p2=57001 p3=128
WAIT #1: nam='db file scattered read' ela=33220 p1=6 p2=57129 p3=128
...
높은 MBRC 수치는 옵티마이저가 Full Table Scan을 선호하도록 영향을 줄 수 있다. 적절한 수치는 애플리케이션(DSS 또는 OLTP)에 따라 다르다. 높은 MBRC 수치는 Full Table Scan 수행을 좀 더 빠르게 수행할 수 있도록 하므로, 배치 처리시 유리할 수 있다.
MBRC 수치는 sstiomax, DB_BLOCK_SIZE 및 DB_BLOCK_BUFFERS 등 몇 가지 요소에 따라 좌우된다. 사용 환경에 맞춰 쉽게 설정하기 위해서는, 위의 예에서 보는 바와 같이 MBRC에 아주 큰 값을 주고 오라클이 시스템에서 처리 가능한 최대값으로 수행하도록 한다.
그 후, Full Table Scan을 수행하는 SQL을 실행시킨 뒤 V$SESSION WAIT 뷰를 조회하면 된다. 그러면 db file scattered read 대기 이벤트의 P3 파라미터의 수치가 현재 시스템의 최댓값이 된다.
다른 방법은 10046 트레이스 이벤트를 설정하는 것이다. 이 최댓값은 데이터베이스 레벨에 설정하기 보다는 Full Table Scan의 수행속도를 향상시킬 필요성이 있는 세션에 대해 설정해야 한다.
direct path read
direct path read 이벤트 대기는 Parallel Query 수행 시 슬레이브 세션(Slave Session)이 수행하는 direct path I/O에 의해 발생한다.
direct path I/O는 SGA 내의 버퍼 캐시를 거치지 않고 세션의 PGA로 직접 블록을 읽어 들이는 것으로 direct read는 I/O방식(synchronous I/O, asynchronous I/O)에 상관없이 수행될 수 있으나 하드웨어 플랫폼과 DISK ASYNCHRONY IO 파라미터에 영향을 받는다.
Parameter
P1 : 절대파일#, P2 : 시작블록#, P3 : 블록 수
Wait Time
I/O를 수행하기 위해 대기한 시간을 의미
일반 문제상황 및 개선방법
Parallel Query의 성능 향상
Parallel Query를 수행하는 과정에서의 direct path read 대기는 필연적인 것으로 이 대기 자체를 튜닝하는 것은 불가능하다. 오히려 SQL 튜닝을 통해 Parallel Query 자체의 성능을 개선하는 것이 방법이다. 시스템의 용량에 비해 불필요하게 Parallel Query를 수행하는 것은 오히려 성능을 저하시키는 요인이 된다. 데이터 파일에 대해 직접 읽기 작업을 수행하기 전에는 읽기의 대상이 되는 객체의 더티 블록이 데이터 파일에 기록이 선행 되어야 한다.. 즉 체크포인트가 발생하게 된다. 이 작업을 수행하는 동안 코디네이터 세션은 enq: TC - connection 대기 이벤트를 발생시킨다.
만약 병렬 쿼리(parallel query) 슬레이브에서 direct reads가 발생한다면, 병렬 스캔(parallel scan)이 parent SQL문에 적합한지와 슬레이브 개수가 적당한지 확인해야 한다. 또한, 쿼리 슬레이브들이 시스템의 CPU와 디스크 자원을 모두 점유하지 않는지도 확인해야 한다.
Direct Path I/O
오라클의 I/O는 기본적으로 버퍼 캐시(SGA)를 경유한다. 하지만 특수한 상황에서는 Buffer Cache를 우회해서 PGA에 데이터를 올린다. 데이터를 공유할 필요가 없을 때는 버퍼 캐시에 데이터를 적재하는 과정에서 발생하는 오버헤드를 피함으로써 성능을 개선하는 것이 가능하다. 버퍼 캐시내의 변경된 블록을 데이터 파일에 기록하는 것은 DBWR 프로세스의 고유의 작업이다. 반면 버퍼 캐시를 우회하는 쓰기 작업은 개별 프로세스가 직접 수행하게 된다. 이처럼 버퍼 캐시를 우회하는 I/O 작업을 direct path I/O라고 부른다.
_DB_FILE_DIRECT_IO_COUNT의 조정
_DB_FILE_DIRECT_IO_COUNT 히든 파라미터의 값이 direct path I/O에서의 최대 I/O 버퍼 크기를 결정한다. 오라클 9i부터 이 값은 기본적으로 1M의 값을 가진다. 하지만 실제로는 OS나 하드웨어 설정에 따라 최댓값이 결정된다. 이 값을 높이면 Parallel Query의 성능이 높아질 수도 있으나, 대부분 실제 사용한 값은 1M보다 작은 값이므로 실제로는 변경할 필요가 없다.
direct path read와 undo
ERROR at line 1 :
ORA-12801: error signaled in parallel query server P002
ORA-01555: snapshot too old: rollback segment number 68 with name "_SYSSMU68$" too small
-- PQ 슬레이브 세션이 데이터 파일에 대해 direct read를 수행하면서 변경된 블록을 발견하면 언두 데이터를 참조
Direct path read가 비록 데이터파일에서 직접 데이터를 읽지만, UNDO를 참조하는 매커니즘은 동일한다. 즉, direct_path_read는 SGA(Shared Global Area)를 경유하지 않을 뿐, 읽기 일관성(Read consistency)을 보장하는 방법은 동일합니다. 이것을 증명하는 방법은 크기가 작은 언두 테이블스페이스(Undo tablespace)를 생성한 후, Parallel Query를 수행하면서 다른 세션에서 DML을 과다하게 수행할 때 ORA-01555(Snapshot too old)에러가 나는 것을 관찰하는 것이다.
DB_FILE_DIRECT_IO_COUNT
DB_FILE_DIRECT_IO_COUNT 파라미터는 direct path read 성능에 영향을 미칠 수 있다. 해당 파라미터는 direct reads, direct writes에 대한 최대 I/O 버퍼 크기로 설정해야 한다. 오라클 8i까지는 대부분의 플랫폼에서 기본 설정 값은 64 블록이었다. 따라서 DB_BLOCK_SIZE가 8k 인 경우 direct reads, direct writes에 대한 최대 I/O 버퍼크기는 512K(8K*64)이다. 최대 I/O 버퍼 크기는 하드웨어의 한계값에 의해서도 제한된다.
오라클 9i에서는 DB_FILE_DIRECT_IO_COUNT 파라미터는 hidden 파라미터로 변경되었고, 블록수가 아니라 바이트(BYTE) 단위로 변경되었다. 오라클 9i의 기본 설정 값은 1MB이다. 실질적인 direct I/O 크기는 하드웨어 환경설정(configuration) 및 한계값에 의해서도 영향을 받는다.
Direct Read I/O 크기 알기
WAIT #1: nam='direct path read' ela=4 p1=4 p2=86919 p3=8
WAIT #1: nam='direct path read' ela=5 p1=4 p2=86927 p3=8
WAIT #1: nam='direct path read' ela=10 p1=4 p2=86935 p3=8
WAIT #1: nam='direct path read' ela=39 p1=4 p2=86943 p3=8
...
direct read를 수행하는 세션에 대해 10046 트레이스 이벤트를 레벨 8로 설정한다. P3 파라미터는 읽은 블록 수를 나타낸다. 위의 예제의 경우, 블록 크기가 8K이므로 direct path read I/O 크기는 64K(8K*8블록)이다. 또한, V$SESSiON_WAIT, V$ACTIVE_SESSION_HISTORY 뷰를 조회하여 direct path read 대기 이벤트의 P3 값을 확인할 수 있다.
데이터 파일에 대한 direct path read의 증명
Session A: Degree가 4인 pq_test 테이블에 대해 PQ를 여러번 수행하면서 direct path read 유발
declare
v_count number;
begin
for idx in 1 .. 100 loop
select count(*) into v_count from pq_test;
end loop;
end;
/
Session B: Session A에서 발생한 PQ의 슬레이브 세션에 대해서 direct path read 이벤트를 캡쳐
(Session A의 SID=162)
set serveroutput on size 100000
declare
begin
for px in (select * from v$px_session where acsid=162) loop
for wait in (select *
from v$session_wait
where sid=px.sid
and event like '%direct path read%') loop
dbms_output.put_line('SID='||wait.sid||',P=1'||wait.P1);
end loop;
end loop;
end;
/
-- Session B의 수행결과
SID=138, P1=1
SID=152, P1=1
SID=144, P1=1
...
SID=142, P1=1
SID=144, P1=1
SID=138, P1=1
-- direct path read 대기 이벤트의 P1 = file# 이므로 해당되는 파일이 실제 데이터 파일인지 확인할 수 있다.
SQL> exec print_table('select * from v$datafile where file#=1');
FILE# : 1
BLOCK_SIZE : 8192
NAME
C:\ORACLE\PRODUCT\10.1.0\ORADATA\UKJADB\SYSTEM01.DEF
PLUGGED_IN : 0
BLCOK1_OFFSET : 8192
AUX_NAME : NONE
-- 위와 같이 system01.dbf 라는 데이터 파일에 대한 direct path read 임을 알 수 있다.
하나의 세션에서 PQ를 수행한 후, PQ가 수행되는 동안 다른 세션에서 V$SESSION_WAIT 뷰를 조회해서 P1 값을 얻으면 어떤 파일에 대한 direct path read 인지 알 수 있다.
direct path write
direct path write 대기 이벤트는 세션 PGA(Program Global Area) 내부의 버퍼로부터 데이터 파일로 기록할 때 발생한다. 세션은 다수의 direct write를 요청한 후 처리를 진행한다. 세션이 I/O 처리가 완료되었다고 인지하는 시점에 direct path write 대기 이벤트를 대기한다.
direct path write 대기는 Direct load 작업이 발생함을 의미한다. 이러한 작업이 요청될 경우 오라클은 SGA(System Global Area)를 경유하지 않고 데이터 파일에 직접 쓰기 작업을 수행한다. 즉, DBWR(Database Writer) 프로세스에 의해 쓰기 작업이 이루어지는 것이 아니라 서버 프로세스에 의해 직접 쓰기 작업이 이루어진다. CTAS나 Insert /*+append*/, Direct 모드로 SQL*Loader를 수행할 때 direct load 작업이 수행된다.
Parameter
P1 : 절대 file#, P2 : 시작 Block#, P3 : 블록 수
Wait Time
I/O 수행하기 위해 대기한 시간을 의미
일반적인 문제 상황 및 개선방법
Direct load 작업의 특징
Direct 모드와 Parallel 모드를 병행해서 수행함으로써 성능을 더욱 극대화 할 수 있다. PCTAS(Parallel CTAS), Insert /*+ parallel(8) append */ 나 direct parallel 모드로 SQL*Loader를 수행하는 것이 대표적인 예이다.
Direct 모드인 경우에는 데이터가 직접 테이블 세그먼트로 기록되지만, Parallel 모드와 병행되는 경우에는 일단 테이블 세그먼트가 속한 영구 테이블스페이스(Paramenant Tablespace)내의 임시 세그먼트(Temporary Segment)에 직접 기록한 다음 모든 작업이 성공적으로 끝난 후에 테이블 세그먼트에 병합된다는 것을 유의해야 한다.
Direct Load 작업 수행시 발생하는 direct path write 대기는 필연적인 것이므로 이 대기의 발생 자체를 줄일 수는 없다. 만일 direct path write 이벤트의 평균대기시간이 지나치게 높게 나온다면 파일시스템 자체의 성능에 문제가 있다고 판단할 수 있다. 비동기식 I/O가 사용될 경우, direct path write 대기 이벤트의 대기횟수와 대기시간은 오해의 소지가 있을 수 있다.
캐싱되지 않은 LOB 세그먼트에 쓰기 I/O 작업시 발생되는 direct path write 대기 이벤트는 오라클 8.1.7부터는 direct path write(lob) 대기 이벤트로 별도로 구분된다.
direct path read temp
정렬작업을 위해 임시 영역을 읽고 쓰는 경우에는 direct path read temp, direct path write temp 이벤트를 대기한다. 이 대기 이벤트들은 오라클 10g 이후에 분화된 것으로 오라클 9i까지는 direct path read, direct path write 대기로 관찰되었다. 정렬 세그먼트에서의 direct path I/O는 정렬해야 할 데이터가 정렬을 위해 할당된 PGA(Program Global Area) 메모리 영역보다 큰 경우에 발생한다.
Parameter
P1 : 절대 파일#, P2 : 시작 블록#, P3 : 블록 수
Wait Time
I/O를 수행하기 위해 대기한 시간
일반적인 문제 상황 및 개선방법
PGA_AGGREGATE_TARGET과 DIRECT I/O
SQL> alter system set PGA_AGGREGATE_TARGET = 200M;
SQL> @show_param max_size
_sum_max_size (Kbyte 단위)
40960
_sum_px_max_size
102400
-- 인덱스를 생성한다. 인덱스 생성 시 내부 정렬작업이 발생
SQL> create index pdm1_idx on pdm1_test(id);
SQL> @sesstat
stat_name 값을 입력하시오 : 'session pga memory max'
==> 44920200
실제 PGA_AGGREGATE_TARGET을 설정한 경우 개별 세션의 PGA값이 어떻게 지정되는지 아래 스크립트를 통해 확인할 수 있다.
PGA_AGGREGATE_TARGET을 그대로 사용하면서 특정 세션에 대해서만 작업 간의 크기를 크게 주고 싶다면, 해당 세션의 PGA관리정책만을 변경하면 된다. 즉, alter session set workarea_size_policy=manual로 변경한 후, alter session set sort_area_size = 1073741824(1G); 을 이용해 값을 설정할 수 있다.
-- PGA 전체 크기를 10M으로 변경
SQL> alter system set pga_aggregate_target = 10M;
-- 정렬 작업 수행
SQL> create index tab_ix on tab(col1);
Index created.
Elapsed. 00:00:40.07
EVENT TOTAL_ WAIT TIME_WAITED
---------------------- --------- ---------------------
SQL*Net message 22 3251
from client
direct path read temp 4953 7
log file sync 2 4
direct path write temp 684 1
SQL*Net message 23 0
to client
direct path write 4 0
evnets in waitclass 1 0
Other
-- PGA 전체 크기를 1G으로 변경
SQL> alter system set pga_aggregate_target = 1G;
-- 정렬 작업 수행
SQL> create index tab_ix on tab(col1);
Index created.
Elapsed. 00:00:28.07
EVENT TOTAL_ WAIT TIME_WAITED
---------------------- --------- ---------------------
SQL*Net message 20 8268
from client
log fiel switch 4 33
completion
log file sync 2 8
SQL*Net message 21 0
to client
evnets in waitclass 1 0
Other
direct path write 4 0
PGA_AGGREGATE_TARGET 값을 적절하게 설정해주는 경우, direct path I/O가 사라지고 이로 인해 direct path read temp, direct path write temp 대기 현상이 완전히 사라지게 되고 성능도 크게 개선된다.
db file parallel read
데이터베이스 복구 수행시 복구해야 하는 블록들을 여러개의 데이터 파일로부터 동시에 읽어들일 때 발생한다. 또한, 하나 이상의 데이터 파일로부터 연속되지 않는 싱글 블록들을 동시에 읽어들이는 Prefetching시에도 발생한다.
Prefetch
한 번에 여러개 Single Block I/O를 동시 수행하는 것이다. 오라클을 포함한 모든 DBMS는 디스크 블록을 읽을 때 곧이어 읽을 가능성이 높은 블록을 미리 읽어오는 Prefetch 기능을 제공한다. 데이터 블록을 읽는 도중에 물리적인 Disk I/O 서브 시스템에 I/O Call을 발생시키고 잠시 대기 시킨다. 대기 상태에서 곧이어 읽을 가능성이 높은 블록들을 버퍼 캐시에 미리 적재해 놓는다면 대기 이벤트 발생횟수를 그만큼 줄일 수 있다. Prefetch db file parallel read 대기 이벤트로 측정된다.
Prefetch는 한 번의 I/O Call로 앞으로 읽을 가능성이 높은 블록을 함께 읽어오는 기능이다. 특히 Clustering Factor가 매우 좋지 않은 인덱스의 경우, 인덱스를 통한 테이블 Access시 1건의 데이터를 읽기 위해 1번의 Single Block I/O가 발생하게 된다.
이런 비효율을 개선하기 위해 1번의 I/O Call시 앞으로 읽을 가능성이 높은 블록을 함께 읽는 Multi Block I/O 기능이다. 이 기능을 사용하여 블록을 읽을 때 목격되는 이벤트가 db file parallel read 이다.
Parameter
P1 : 동시에 읽고 있는 파일 수, P2 : 읽고 있는 총 블록 수, P3 : 총 I/O 요청 횟수(Multi Block I/O를 하지 않는 경우 P2와 동일)
Wait Time
I/O를 수행하기 위해 대기한 시간을 의미
일반적인 문제 상황 및 대처방안
db file parallel write
DBWR이 더티 블록을 기록하기 위해 I/O 요청을 보낸 후, 요청이 끝나기를 기다리는 동안 대기하는 이벤트이다. db file parallel write 대기는 기본적으로 I/O 이슈이다.
DBWR 프로세스에서 이 대기가 광범위하게 나타난다면 데이터 파일과 관련된 I/O 시스템에 심각한 성능 저하 현상이 발생한 것으로 판단할 수 있다. 만일 I/O 시스템의 성능에 문제가 없는데도 db file parallel write 대기가 사라지지 않는다면 그때는 I/O 시스템이 감당할 수 없을 정도의 많은 쓰기 요청이 발생하는 것으로 간주할 수 있다.
db file parallel read 대기 이벤트와 동일하게 병렬 처리(parallel DML)과 연관이 없다. 버퍼 캐시를 경유하는 모든 데이터는 DBWR 프로세스에 의해 디스크에 기록이 된다. DBWR 프로세스가 더티 블록을 기록하기 위한 I/O 요청을 보낸 후 요청이 끝나기를 기다리는 동안 db file parallel write 이벤트를 대기하게 된다.
DBWR 프로세스는 한번의 I/O 요청을 통해
control file parallel write
read by other session
write complete waits
참조 사이트 : 12bme.it story.com/311
| Oracle Lock 튜닝 (0) | 2025.04.04 |
|---|---|
| Oracle Library Cache (0) | 2025.04.04 |
| Oracle _optimizer_gather_stats_on_load (0) | 2025.04.02 |
| Oracle 19c 공간관리 및 Direct Path Load (0) | 2025.04.02 |
개요 : 오라클 전환에서 direct insert 실행시 통계 정보 off
alter system set "_optimizer_gather_stats_on_load"=FALSE;
INSERT /*+ APPEND PARALLEL(8) no_gather_optimizer_statistics */
| Oracle Lock 튜닝 (0) | 2025.04.04 |
|---|---|
| Oracle Library Cache (0) | 2025.04.04 |
| Oracle I/O 대기 이벤트 (0) | 2025.04.03 |
| Oracle 19c 공간관리 및 Direct Path Load (0) | 2025.04.02 |
개요 : Oracle 19c 의 ASM 환경에서 디스크 10tb 추가 후 전환 시에 급격히 느려 지는 현상 발생
포인트 : 아래 대기 이벤트 대량 발생함
CTAS 실행 시에 TSM 이 아니라 12c 에서 HYBRID TSM/HWMB 방식으로 수행되어 세션에서 아래 파라미터를 설정하여 TSM방식으로 수행한다.
TSM loading은 각 병렬 프로세스(PX server)가 자체 임시 세그먼트 전용이므로 데이터를 로드하는 각 프로세스 간에 상당한 격리가 있기 때문에 DOP(병렬도 Degree of Parallel)에 따라 확장이 되어 DOP가 높을수록 높은 성능을 보인다.
단점은 각 임시 세그먼트는 테이블의 일부가 될 때 적어도 각각 하나의 익스텐드가 된다. DOP가 8개라면 테이블에 최소한 8개의 새 익스텐트를를 추가하게 되어 공간의 낭비가 일어날 수 있다. 여기는 대량의 데이터가 발생하는 전환 환경이라서 TSM 방식으로 수행한다.
-- default : LOAD AS SELECT ((HYBRID TSM/HWMB)) 방식으로 변경
alter session set "_px_hybrid_TSM_HWMB_load"=true;
alter session set "_force_tmp_segment_loads"=false;
[오렌지 예상 실행계획 ctrl+e]
CREATE TABLE STATEMENT OPTIMIZER=ALL_ROWS
PX COORDINATOR
PX SEND (QC (RANDOM)) OF 'SYS:TQ10000' (Cost=57K Card=131M Bytes=20G) (PARALLEL_TO_SERIAL) (QC (RANDOM))
LOAD AS SELECT ((HYBRID TSM/HWMB)) OF 'TABLE_01' (PARALLEL_COMBINED_WITH_PARENT)
OPTIMIZER STATISTICS GATHERING (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_PARENT)
PX BLOCK (ITERATOR) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_CHILD)
TABLE ACCESS (STORAGE FULL) OF 'MDSPRD.ON_BYDY_CHNL_SALS_PCAL_ENR_P' (TABLE) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_PARENT)
-- LOAD AS SELECT ((TEMP SEGMENT MERGE)) 방식으로 변경
alter session set "_px_hybrid_TSM_HWMB_load"=false;
alter session set "_force_tmp_segment_loads"=true;
[오렌지 예상 실행계획 ctrl+e]
CREATE TABLE STATEMENT OPTIMIZER=ALL_ROWS
PX COORDINATOR
PX SEND (QC (RANDOM)) OF 'SYS:TQ10000' (Cost=57K Card=131M Bytes=20G) (PARALLEL_TO_SERIAL) (QC (RANDOM))
LOAD AS SELECT ((TEMP SEGMENT MERGE)) OF 'TABLE_01' (PARALLEL_COMBINED_WITH_PARENT)
OPTIMIZER STATISTICS GATHERING (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_PARENT)
PX BLOCK (ITERATOR) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_CHILD)
TABLE ACCESS (STORAGE FULL) OF 'MDSPRD.ON_BYDY_CHNL_SALS_PCAL_ENR_P' (TABLE) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_PARENT)
-- 통계정보 OFF
alter session set "_optimizer_gather_stats_on_load" = FALSE;
[오렌지 예상 실행계획 ctrl+e]
CREATE TABLE STATEMENT OPTIMIZER=ALL_ROWS
PX COORDINATOR
PX SEND (QC (RANDOM)) OF 'SYS:TQ10000' (Cost=57K Card=131M Bytes=20G) (PARALLEL_TO_SERIAL) (QC (RANDOM))
LOAD AS SELECT ((TEMP SEGMENT MERGE)) OF 'TABLE_01' (PARALLEL_COMBINED_WITH_PARENT)
PX BLOCK (ITERATOR) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_CHILD)
TABLE ACCESS (STORAGE FULL) OF 'MDSPRD.ON_BYDY_CHNL_SALS_PCAL_ENR_P' (TABLE) (Cost=57K Card=131M Bytes=20G) (PARALLEL_COMBINED_WITH_PARENT)
오라클 space management and oracle direct path load 내용 발췌
Oracle에서 병렬 데이터 로딩에 사용하는 첫 번째 메커니즘이며 Oracle 11.2에서 단일 세그먼트로의 병렬 로딩을 위한 기본 메커니즘이다.
-- 일반테이블에 대한 Parallel Create Table as Select(PCTAS)
CREATE TABLE sales_copy PARALLEL 8 AS SELECT * FROM sales;
-- 일반테이블 또는 단일 파티션에 대한 Parallel Insert Direct Load(PIDL)
INSERT /*+ APPEND PARALLEL(t1 8) INTO sales_copy_nonpart t1 SELECT ...;
INSERT /*+ APPEND PARALLEL(t1 8) INTO sales_copy PARTITION (part_p1) a SELECT ...;
병렬 데이터 로딩이 시작되면 각 병렬 프로세스는 임시 세그먼트에 할당된다.
임시 세그먼트는 로드되는 테이블 또는 파티션과 동일한 테이블스페이스에 상주하며 Commit 시 임시 세그먼트는 익스텐트 맵을 조작하여 기본 세그먼트와 병합된다. 즉, 임시 세그먼트는 데이터를 두번 이동하지 않고 테이블이나 파티션에 통합된다.
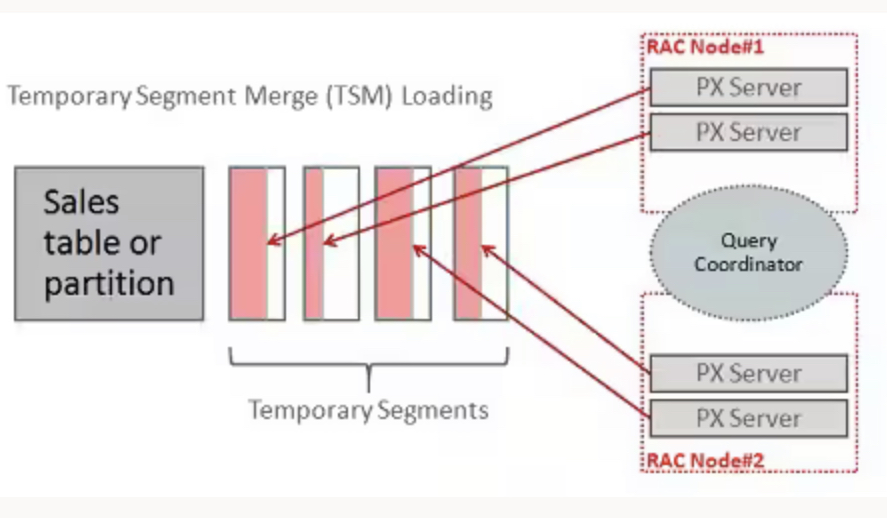
TSM Loading은 각 병렬 프로세스(PX server)가 자체 임시 세그먼트 전용이므로 데이터를 로드하는 각 프로세스 간에 상당한 격리가 있기 때문에 DOP(Degree of Parallel)에 따라 매우 잘 확장된다. 일반적으로는 리소스가 될때까지 DOP가 높을수록 더 많은 성능을 제공하는 것을 기대할 수 있다.
잠재적인 단점은 각 임시 세그먼트는 테이블이나 파티션의 일부가 될 때 적어도 각각 하나의 익스텐트가 된다. DOP가 16에서 로드하는 경우 행 수가 상대적으로 적더라도 테이블에 최소한 16개의 새 익스텐트를 추가한다.(공간의 낭비)
소량의 데이터를 자주 로드하는 것보다 대량의 데이터를 상대적으로 드물게 로드하는 경우 이러한 단점을 보완할 수 있다.
여러 병렬 프로세스가 잠재적으로 동일한 테이블 또는 파티션 세그먼트를 채울 수 있는 경우 HWMB(High Water Mark Brokering)을 사용할 수 있다. 여러 파티션으로 Direct Path Loading을 실행할 때 종종 사용된다.
INSERT /*+ APPEND PARALLEL(t1 8) */ INTO sales_copy_partitioned t1 SELECT ...;
Auto DOP가 사용되는 경우 Oracle 11.2의 단일 세그먼트 로드(일반 테이블 or 특정 파티션)에 대한 기본값이다.
HWM Loading과 마찬가지로, 새로운 데이터가 기존 HWM 위에 직접 추가된다. 옵티마이저가 선택한 DOP 및 병렬 실행계획 유형에 따라 여러 병렬 프로세스가 동일한 세그먼트에 데이터를 삽입할 수 있다. 이 상황에서는 여러 프로세스와 심지어 데이터베이스 서버간 HWM의 위치를 조정하거나 중재해야 한다. 브로커링은 HV enqueue를 사용하여 구현된다. 각 세그먼트에는 고유한 HV enqueue가 있으며 이는 트랜잭션이 커밋되면 HWM의 이동해야 하는 위치를 기록하는데 사용된다. HV enqueue는 여러 프로세스가 동시에 HWM의 위치값을 업데이트 할 수 없도록 한다.

위의 그림은 단일 인스턴스에서 DOP가 4인 경우에 HWM 조정 시를 표한하고 있다.
일반적으로 HWMB는 TSM보다 테이블(또는 단일 파티션) 세그먼트에 추가되는 범위가 더 적다(작은 공간 사용). 이 이점은 데이터를 자주 로드하는 시스템과 높은 DOP를 활용하여 데이터 로드 경과 시간을 줄이는 시스템에서 중요하다.
Oracle 12.1부터의 변경사항은 특히 일반 테이블 또는 단일 파티션 세그먼트를 Insert 할 때 사용되는 병렬 Direct Path Loading의 확장성을 향상시킨다. 일반 테이블과 단일 파티션 간에 데이터를 이동하고 변환하는 고성능 환경에서 특히 중요하고, Partition Exchange 작업을 사용하여 파티션된 테이블에 일반 테이블이 채워지는 환경에서도 유용하다
INSERT /*+ APPEND PARALLEL(t1 8) */
INTO sales_copy t1 /* sales_copy is not partitioned */
SELECT /*+ PARALLEL(t2 8) */ *
FROM sales t2; /* sales is not partitioned */
실행계획은 다음과 같다.
--------------------------------------------------------------------------------------------------------------------------
| Id | Opreation | Name | Rows | Bytes| Cost (%CPU)| Time | TQ |IN-OUT| PQ Distib |
--------------------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | | | 73(100)| | | | |
| 1 | PX CORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10000 | 1000K| 8789K| 73 (2)|00:00:01| Q1,00 | P->S | QC (RAND) |
| 3 | LOAD AS SELECT (HYBRID TSM/HWMB) | SALES_DL_COPY| | | | | Q1,00 | PCWP | |
| 4 | PX BLOCK ITERATOR | | 1000K| 8789K| 73 (2)|00:00:01| Q1,00 | PCWC | |
|* 5 | TABLE ACCESS FULL | SALES_DL | 1000K| 8789K| 73 (2)|00:00:01| Q1,00 | PCWP | |
--------------------------------------------------------------------------------------------------------------------------TSM과 HWMB의 장점을 결합한 하이브리드 솔루션이다.
해당 방식의 주된 목적은 단일 세그먼트에 Insert 하기 위해 큰 DOP를 사용하는 경우 HWMB 방식은 불리하다.
단일 HV enqueue는 자주 업데이트가 되어야 하므로 병렬 프로세스가 RAC 환경에 분산되어 있는 경우에는 잠재적인 경합지점이 더 중요해진다. 전체 클러스터에서 사용중인 HV enqueue에 대한 엑세스를 직렬화하는 것은 시간이 많이 소요될 수 있으므로 HV enqueue에 대한 인스턴스 간의 경합을 제거하는 동시에 새로운 익스텐스의 수를 줄이도록 TSM과 HWMB를 결합한다.
(여기서 최적화가 발생할 가능성이 가장 높기 때문) 병렬 로드작업이 시작되면 로드와 관련된 각 인스턴스에 대해 임시세그먼트가 생성된다.(클러스터 전체에 분산된 경우 2노드 RAC 클러스터라면 2개의 임시 세그먼트가 있다)
각 임시 세그먼트는 여러 병렬 프로세스에서 로드할 수 있지만 데이터베이스는 각 임시 세그먼트가 단일 인스턴스노드에서 병렬 프로세스에 의해 로드되도록 한다. 이러한 방식으로 각 임시 세그먼트와 연결된 HV enqueue는 각 데이터베이스 인스턴스에 대해 로컬로 중개되며 전체 클러스터에서 중개될 필요가 없다.
아래 그림은 DOP 4의 Hybrid TSM/HWMB 로드를 나타낸다.
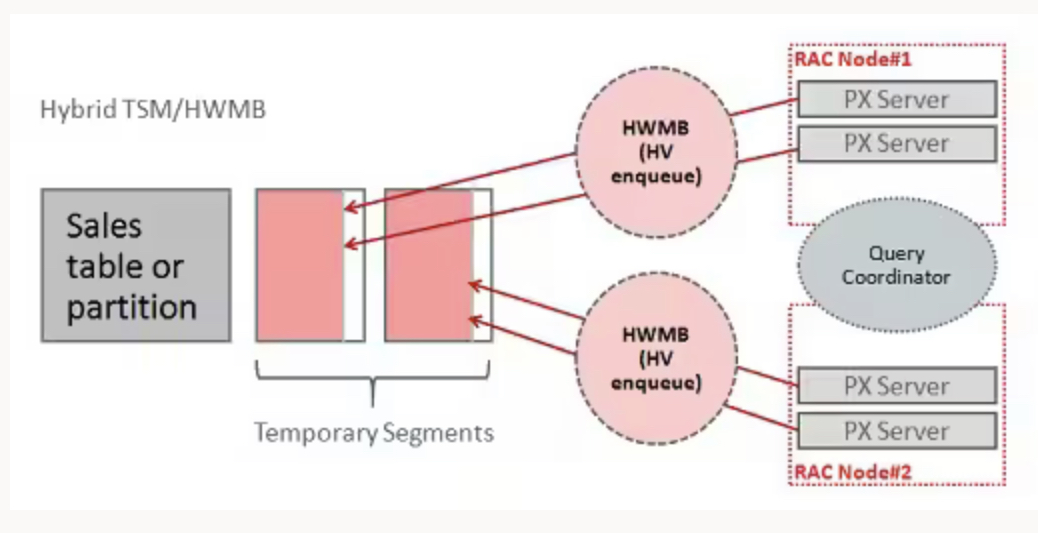
요약하면 Hybrid TSM/HWMB의 이점은 다음과 같다
Oracle 12c에서
전환 환경에서는 Hybrid TSM/HWMB를 일으키는 TCTAS (partition) 문장이 대기 이벤트 HV - contention을 발생시킨다. 해당 방식을 끄고 TSM 방식으로 사용해야 한다.
추가 내용 :
ASSM에서 HW 락 경합이 일어나면 익스텐트 크기를 조정할 수 있다.
HW락을 줄이는 방법은 FLM보다는 ASSM을 사용하고 적절한 익스텐트를 사용하며 LMT(Locally Managed Tablespace)를 사용해야 하고 특별한 경우가 아니라면 Uniform Size의 익스텐트를 사용하며 충분한 크기의 익스텐트를 사용한다.
참조 블로그
12bme.it story.com/312
https://blogs.oracle.com/optimizer/post/space-management-and-oracle-direct-path-load
bae9086.it story.com/486
blog.naver.com/miplus/222047422331
| Oracle Lock 튜닝 (0) | 2025.04.04 |
|---|---|
| Oracle Library Cache (0) | 2025.04.04 |
| Oracle I/O 대기 이벤트 (0) | 2025.04.03 |
| Oracle _optimizer_gather_stats_on_load (0) | 2025.04.02 |
[code.bat]
@ECHO OFF
sqlplus SCOTT/TIGER@ORCL @"D:/code/code_loader1.sql">"D:/code/log.txt"
sqlldr SCOTT/TIGER@ORCL control='D:/code/code.ctl' log='D:/code/loader_log.txt'
sqlplus SCOTT/TIGER@ORCL @"D:/code/code_loader2.sql">>"D:/code/log.txt"
EXIT
1. ASIS코드 매핑결과 적재테이블
[code.loader1.sql]
DROP TABLE EN_ASIS_CD_DATA;
CREATE TABLE EN_ASIS_CD_DATA(
"순번" NUMBER,
"주제영역FULL명" VARCHAR2(1000),
"주제영역명" VARCHAR2(1000),
"모델명" VARCHAR2(1000),
"엔터티명" VARCHAR2(1000),
"테이블명" VARCHAR2(1000),
"속성명" VARCHAR2(1000),
"컬럼명" VARCHAR2(1000),
"테이블명컬럼명" VARCHAR2(1000),
"데이터타입" VARCHAR2(1000),
"데이터길이" VARCHAR2(1000),
"데이터소수점자리" VARCHAR2(1000),
"PK여부" VARCHAR2(1000),
"NULL여부" VARCHAR2(1000),
"코드구분" VARCHAR2(1000),
"공통코드엔터티명" VARCHAR2(1000),
"코드추출소스" VARCHAR2(1000),
"참조코드테이블명" VARCHAR2(4000),
"참조코드컬럼명" VARCHAR2(1000),
"참조코드ID" VARCHAR2(1000),
"코드오류존재여부" VARCHAR2(1000)
)
NOLOGGING;
EXIT;
2. 엑셀데이터 테이블에 넣어서 script파일 만들기
-- 누락 확인
-- 누락 확인
create table tmp_dual
as
select rownum no from dual connect by level <= 27206;
select no
from tmp_dual a
where not exists (select /*+anti_sj*/ 순번
from EN_ASIS_CD_DATA x
where x.순번 = a.no)
;
-- chr(10)이 행 두개로 분리되는 현상 제거, 스페이스 한개이상 -> 한개로 변환
select repexp_replace(replace(참조코드테이블명,chr(10),'##enter##'),'( )+',chr(32))
from EN_ASIS_CD_DATA
where instr(참조코드테이블명,chr(10))>0;
-- 아래 sql 실행결과를 code_script2.sql로 저장.
select
순번
||'||||'||NVL(TRIM(주제영역FULL명),'NULL')
||'||||'||NVL(TRIM(주제영역명),'NULL')
||'||||'||NVL(TRIM(모델명),'NULL')
||'||||'||NVL(TRIM(엔터티명),'NULL')
||'||||'||NVL(TRIM(테이블명),'NULL')
||'||||'||NVL(TRIM(속성명),'NULL')
||'||||'||NVL(TRIM(컬럼명),'NULL')
||'||||'||NVL(TRIM(테이블명컬럼명),'NULL')
||'||||'||NVL(TRIM(데이터타입),'NULL')
||'||||'||NVL(TRIM(데이터길이),'NULL')
||'||||'||NVL(TRIM(데이터소수점자리),'NULL')
||'||||'||NVL(TRIM(PK여부),'NULL')
||'||||'||NVL(TRIM(NULL여부),'NULL')
||'||||'||NVL(TRIM(코드구분),'NULL')
||'||||'||NVL(TRIM(공통코드엔터티명),'NULL')
||'||||'||NVL(TRIM(코드추출소스),'NULL')
||'||||'||NVL(regexp_replace(replace(TRIM(참조코드테이블명),chr(10),'##enter##'),'( )+',chr(32)),'NULL')
||'||||'||NVL(TRIM(참조코드컬럼명),'NULL')
||'||||'||NVL(TRIM(참조코드ID),'NULL') script
from EN_ASIS_CD_DATA
order by 순번
;
3. code_script2.sql파일 loader로 삽입
[code.ctl]
load data
infile 'D:/code/code_script2.sql'
append
into table SCOTT.EN_ASIS_CD_DATA
fields terminated by '||||'
trailing nullcols
(
순번
,주제영역FULL명
,주제영역명
,모델명
,엔터티명
,테이블명
,속성명
,컬럼명
,테이블명컬럼명
,데이터타입
,데이터길이
,데이터소수점자리
,PK여부
,NULL여부
,코드구분
,공통코드엔터티명 char(1000)
,코드추출소스 char(1000)
,참조코드테이블명 char(1000)
,참조코드컬럼명 char(1000)
,참조코드ID char(1000)
,코드오류존재여부 char(1000)
)
4. ##enter-> chr(10) NULL문자-->NULL값으로 치환 후 인덱스 생성
[code_loader2.sql]
update
(
select
순번,decode(순번,'NULL','','순번') as upd_순번
,주제영역FULL명,decode(주제영역FULL명,'NULL','',주제영역FULL명) as upd_주제영역FULL명
,주제영역명,decode(주제영역명,'NULL','',주제영역명) as upd_주제영역명
,모델명,decode(모델명,'NULL','',모델명) as upd_모델명
,엔터티명,decode(엔터티명,'NULL','',엔터티명) as upd_엔터티명
,테이블명,decode(테이블명,'NULL','',테이블명) as upd_테이블명
,속성명,decode(속성명,'NULL','',속성명) as upd_속성명
,컬럼명,decode(컬럼명,'NULL','',컬럼명) as upd_컬럼명
,테이블명컬럼명,decode(테이블명컬럼명,'NULL','',테이블명컬럼명) as upd_테이블명컬럼명
,데이터타입,decode(데이터타입,'NULL','',데이터타입) as upd_데이터타입
,데이터길이,decode(데이터길이,'NULL','',데이터길이) as upd_데이터길이
,데이터소수점자리,decode(데이터소수점자리,'NULL','',데이터소수점자리) as upd_데이터소수점자리
,PK여부,decode(PK여부,'NULL','',PK여부) as upd_PK여부
,NULL여부,decode(NULL여부,'NULL','',NULL여부) as upd_NULL여부
,코드구분,decode(코드구분,'NULL','',코드구분) as upd_코드구분
,공통코드엔터티명,decode(공통코드엔터티명,'NULL','',공통코드엔터티명) as upd_공통코드엔터티명
,코드추출소스,decode(코드추출소스,'NULL','',코드추출소스) as upd_코드추출소스
,참조코드테이블명,decode(참조코드테이블명,'NULL','',참조코드테이블명) as upd_참조코드테이블명
,참조코드컬럼명,decode(참조코드컬럼명,'NULL','',참조코드컬럼명) as upd_참조코드컬럼명
,참조코드ID,decode(참조코드ID,'NULL','',참조코드ID) as upd_참조코드ID
,코드오류존재여부,decode(코드오류존재여부,'NULL','',코드오류존재여부) as upd_코드오류존재여부
from EN_ASIS_CD_DATA
)
set
순번=upd_순번
,주제영역FULL명=upd_주제영역FULL명
,주제영역명=upd_주제영역명
,모델명=upd_모델명
,엔터티명=upd_엔터티명
,테이블명=upd_테이블명
,속성명=upd_속성명
,컬럼명=upd_컬럼명
,테이블명컬럼명=upd_테이블명컬럼명
,데이터타입=upd_데이터타입
,데이터길이=upd_데이터길이
,데이터소수점자리=upd_데이터소수점자리
,PK여부=upd_PK여부
,NULL여부=upd_NULL여부
,코드구분=upd_코드구분
,공통코드엔터티명=upd_공통코드엔터티명
,코드추출소스=upd_코드추출소스
,참조코드테이블명=upd_참조코드테이블명
,참조코드컬럼명=upd_참조코드컬럼명
,참조코드ID=upd_참조코드ID
,코드오류존재여부=upd_코드오류존재여부
;
update EN_ASIS_CD_DATA
set 참조코드테이블명 = replace(참조코드테이블명,'##enter##',chr(10))
;
CREATE INDEX EN_ASIS_CD_DATA_IDX01 ON EN_ASIS_CD_DATA(테이블명,컬럼명) NOLOGGING;
exit;
5.시뮬레이션 SQL
SELECT 'SELECT ' AS SQLSCRIPT
FROM DUAL
UNION ALL
SELECT SQLSCRIPT
FROM(
SELECT CASE WHEN TO_NUMBER(A.COLUMN_ID) = 1 THEN '' ELSE ',' END
||RPAD(A.COLUMN_NAME,34)||' AS '||RPAD(SUBSTRB('"'||NVL(B.COMMENTS,B.COLUMN_NAME)||'"',1,32),32)||'--'||A.DATA_TYPE||'('||A.DATA_LENGTH||')'||'--'||I.INDEX_NAME
||CASE WHEN D.참조코드테이블명 LIKE '%APPS.VW_CMMN_CD_NM_01%' THEN CHR(13)||',(SELECT CODE.CMMN_CD_NM FROM APPS.VW_CMMN_CD_NM_01 CODE '||CHR(13)||'WHERE CODE.CMMN_KD_CD='''||참조코드ID||''' AND CODE.CMMN_CD=A.'||A.COLUMN_NAME||') AS '||SUBSTRB('''[공통'||참조코드ID||']'||B.COMMENTS,1,28)||'"'
WHEN D.참조코드컬럼명 LIKE '%SEGMENT1%' THEN CHR(13)||',(SELECT CODE.DESCRIPTION FROM MTL_SYSTEM_ITEMS_B CODE '||CHR(13)||'WHERE CODE.SEGMENT1=A.'||A.COLUMN_NAME||' AND ROWNUM<=1) AS '||SUBSTRB('"[상품]'||B.COMMENTS,1,28)||'"'
WHEN D.참조코드테이블명 IS NOT NULL THEN 코드구분||'-'||참조코드테이블명||'-'||참조코드컬럼명 END AS SQLSCRIPT
FROM ALL_TAB_COLUMNS A
,ALL_COL_COMMENTS B
,ALL_TAB_COLS C
,EN_ASIS_CD_DATA D
,ALL_IND_COLUMNS I
WHERE A.OWNER = B.OWNER
AND B.OWNER = C.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
AND A.TABLE_NAME = C.TABLE_NAME
AND A.COLUMN_NAME = C.COLUMN_NAME
AND C.VIRTUAL_COLUMN != 'YES'
AND A.TABLE_NAME = D.테이블명(+)
AND A.COLUMN_NAME = D.컬럼명(+)
AND A.OWNER = :L_OWNER
AND A.TABLE_NAME = :L_TABLE_NM
AND A.OWNER = I.TABLE_OWNER(+)
AND A.TABLE_NAME = I.TABLE_NAME(+)
AND A.COLUMN_NAME = I.COLUMN_NAME(+)
AND REGEXP_LIKE(I.INDEX_NAME(+),'(^PK_)|)_PK$)')
ORDER BY A.COLUMN_ID
)
UNION ALL
SELECT 'FROM '||:L_OWNER||'.'||:L_TABLE_NM||' A
WHERE 1=1
;'
FROM DUAL;QL
| [10g]데이터 시뮬레이션 comments 쿼리(ver.1) (0) | 2024.11.12 |
|---|---|
| LOB Table Nologging 조회 (1) | 2024.11.12 |
| PL/SQL ASIS 에서 TOBE로 복제시 오류 (0) | 2024.11.12 |
| 배치파일 & SPOOL ON (0) | 2024.11.12 |
| Insert into values 스크립트 추출 쿼리 (0) | 2024.11.12 |