MySQL에서만 사용되는 연산자나 표기법도 함께 살펴보겠지만 SQL 가독성을 높기기 위해 ANSI 표준 형태의 연산자를 사용하길 권장한다.
1.리터럴 표기법
1) 문자열
[ANSI_QUOTES 설정 OFF]
show variables like '%sql_mode%';
set sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_ALL_TABLES,STRICT_TRANS_TABLES,IGNORE_SPACE,PIPES_AS_CONCAT';
SQL 표준에서 문자열은 항상 홑따옴표(')를 사용해서 표시한다. 하지만 MySQL에서는 다음과 같이 쌍 따옴표를 사용해서 문자열을 표기할 수도 있다.
select * from departments where dept_no = 'd001';
select * from departments where dept_no = "d001"; -- MySQL에서만 가능
SQL 표준에서 문자열 값에 홑따옴표(')가 포함돼 있을 떄 홑따옴표를 두 번 연속해서 입력하면 된다. 하지만 MySQL에서는 쌍따옴표와 홑따옴표를 혼합해서 사용하기도 한다.
select * from departments where dept_no = 'd''001';
select * from departments where dept_no = 'd"001';
select * from departments where dept_no = "d'001"; -- MySQL에서만 가능
select * from departments where dept_no = "d""001"; -- MySQL에서만 가능
SQL에서 사용되는 식별자(테이블이나 컬럼명 등)가 키워드와 충돌할때 오라클이나 MS-SQL에서는 쌍따옴표나 대괄호로 감싸서 충돌을 피한다. MySQL에서는 역따옴표로 감싸서 사용하면 예약어와의 충돌을 피할 수 있다.
drop table tb_test;
-- DDL에서 식별자에 쌍따옴표 사용하면 에러난다.
create table tb_test ("table" varchar(20) not null, "column" int);
-- 역따옴표 항상 가능
create table tb_test (`table` varchar(20) not null, `column` int);
select `column` from tb_test; -- 역따옴표 항상 가능
select "column" from tb_test; -- 쌍따옴표 항상 가능
ANSI_QUOTES 설정하면 쌍따옴표는 문자열 리터럴 표기에 사용할 수 없다.
테이블명이나 컬럼명의 충돌을 피할려면 역 따옴표(')가 아니라 쌍따옴표를 사용해야 한다.
[ANSI_QUOTES 설정 ON]
set sql_mode = 'ANSI_QUOTES,ONLY_FULL_GROUP_BY,STRICT_ALL_TABLES,STRICT_TRANS_TABLES,IGNORE_SPACE,PIPES_AS_CONCAT';
select * from departments where dept_no = 'd001';
-- 문자열에 쌍따옴표 사용하면 에러난다.
select * from departments where dept_no = "d001";
drop table tb_test;
create table tb_test (`table` varchar(20) not null, `column` int); -- 역따옴표 항상 가능
create table tb_test ("table" varchar(20) not null, "column" int); -- 쌍따옴표 가능
select `column` from tb_test; -- 역따옴표 항상 가능
select "column" from tb_test; -- 쌍따옴표 항상 가능
전체적으로 MySQL의 고유한 방법은 배제하고 SQL표준 표기법만 사용할 수 있게 강제하려면 sql_mode 시스템 변수 값에 "ANSI"를 설정하면된다. 하지만 이 설정은 대부분 쿼리의 작동 방식에 영향을 미치므로 프로젝트 초기에 적용해야한다. 운용중인 애플리케이션에서 sql_mode 설정을 변경하는 것은 상당히 위험하므로 주의해야 한다.
2) 숫자
두 비교 대상이 문자열과 숫자 타입으로 다를 때는 자동으로 타입의 변환이 발생한다. MySQL은 숫자 타입과 문자열 타입간의 비교에서 숫자 타입을 우선시하므로 문자열 값을 숫자 값으로 변환한 후 비료를 수행한다.
select * from tab_test where number_column = '10001';
위 쿼리는 상수값을 숫자로 변환하므로 성능과 관련된 문제가 발생하지 않는다.
select * from tab_test where string_column = 10001;
위 쿼리는 주어진 상수값이 숫자 값인데 비교되는 컬럼은 문자열 컬럼이다. MySQL은 문자열 컬럼을 숫자로 변환해서 비교한다. 즉, string_column 컬럼의 모든 문자열 값을 수잦로 변환해서 비교해야 하므로 string_column에 인덱스가 있더라도 이용하지 못한다. 만약 string_column에 알파벳 같은 문자가 포함된 경우에는 숫자 값으로 변환할 수 없으므로 쿼리 자체가 실패할 수도 있다.
3) 날짜
다른 DBMS에서 날짜 타입을 비교하거나 INSERT 하려면 반드시 문자열을 DATE 타입으로 변환하는 코드가 필요하다. 하지만 MySQL에서는 정해진 형태의 날짜 포맷으로 표기하면 MySQL 서버가 자동으로 DATE나 DATETIMEE 값으로 변환하기 때문에 복잡하게 STR_TO_DATE()와 같은 함수를 사용하지 않아도 된다.
select * from dept_emp where from_date = '2011-04-29';
select * from dept_emp where from_date = STR_TO_DATE('2011-04-29','%Y-%m-%d');
첫 번째 쿼리와 같이 날짜 타입의 컬럼과 문자열 값을 비교하는 경우, MySQL서버는 문자열 값을 DATE 타입으로 변환해서 비교한다. 두 번째 쿼리는 SQL에서 문자열을 DATE 타입으로 강제 변환해서 비교하는 예제인데, 이 두 쿼리의 차이점은 거의 없다. 첫 번째 쿼리에서 from_date 타입을 문자열로 변환해서 비교하지 않기 때문에 from_date 컬럼으로 생성된 인덱스를 이용하는데 문제가 되지 않는다.
4) BOOLEAN
BOOL이나 BOOLEAN이라는 타입이 있지만 이것은 TINYINT 타입에 대한 동의어일 뿐이다. 테이블의 컬럼을 BOOL로 생성한 뒤에 조회해보면 컬럼의 타입이 BOOL이 아니라 TINYINT라는 점을 알 수 있다. MySQL에서는 다음 예제 쿼리와 같이 TRUE 또는 FALSE 형태로 비교하거나 값을 저장할 수 있다. 하지만 이는 BOOL 타입뿐 아니라 숫자 타입의 컬럼에도 모두 적용되는 비교 방법이다.
drop table tb_boolean;
CREATE TABLE tb_boolean(
col_int int NOT NULL,
col_boolean BOOLEAN,
PRIMARY KEY (col_int)
) ENGINE=InnoDB DEFAULT CHARSET=euckr COLLATE=euckr_bin;
insert into tb_boolean values(0,FALSE);
insert into tb_boolean values(1,true);
insert into tb_boolean values(2,2);
insert into tb_boolean values(3,3);
select * from tb_boolean where col_boolean = false;
select * from tb_boolean where col_boolean = true;
select * from tb_boolean where col_boolean in (true,false);
select * from tb_boolean where col_boolean in (0,1);
select * from tb_boolean where col_int in (true,false);
TRUE나 FALSE로 비교했지만 실제로는 값을 조회해 보면 0 또는 1 값이 조회된다. 즉 MySQL은 C/C++ 언어에서처럼 TRUE 또는 FALSE 같은 불리언 값을 정수로 맵핑해서 사용하는 것이다. MySQL에서는 FASLE가 정수값 0 이고 TRUE는 1만을 의미한다. 그래서 숫자 값이 저장된 컬럼을 TRUE나 FALSE로 조회하면 0 이나 1 이외의 숫자 값은 조회되지 않는다.
모든 숫자 값이 TRUE나 FALSE로 매핑되지 않기 때문에 BOOLEAN 타입을 사용하고 싶다면 ENUM 타입으로 관리하는 것이 명확하다. 실제로 ENUM 컬럼은 데이터 값만 저장해야하는 테이블 컬럼에 데이터 값을 명시하여 정규화에 위반되고 데이터 수정이 어려워 사용을 권장하지 않는다.
2. MySQL 연산자
1) 동등(Equal) 비교 ( =, <=> )
MySQL에서는 동등 비교를 위해 "<=>" 연산자도 제공한다. "<=>" 연산자는 "=" 연산자의 기능에 부가적으로 NULL 값에 대한 비교까지 수행한다. MySQL에서는 이 연산자를 NULL-safe 비교 연산자라고 한다.
select 1 = 1, null = null, 1 = null
union all
select 1 <=> 1, null <=> null, 1 <=> null ;
위 결과에서도 알 수 있듯이 NULL은 "IS NULL"연산자 이외에는 비교할 방법이 없다. 그래서 첫번째 쿼리에서 한쪽이 NULL이면 비교 결과도 NULL로 반환한 것이다. 하지만 NULL-safe 비교 연산자를 이용해 비교한 결과를 보면 양쪽 비교 대상 모두 NULL이라면 TRUE를 반환하고, 한쪽만 NULL이라면 FALSE를 반환하다. 즉 "<=>" 연산자는 NULL을 하나의 값으로 인식하고 비교하는 방법이라고 볼수 있다.
2) 부정(Not-Equal) 비교 ( <>, != )
"같지 않다" 비교를 위한 연산자로 "<>", "!=" 를 사용한다. 가독성을 위해서 하나만 사용하는 것을 권장한다.
3) NOT 연산자 (!)
TRUE 또는 FALSE 연산의 결과를 반대로 만드는 연산자로 "NOT"과 "!"를 사용한다.
select ! 1, ! false, ! true, not 1, not 0, not (1=1);
4) AND(&&) 와 OR(||) 연산자
BOOLEAN 표현식의 결과를 결합하기 위해 AND나 OR를 사용한다. MySQL에서는 AND와 OR뿐만이 아니라 "&&"와 "||"의 사용도 허용하고 있다. "&&"는 AND 연산자와 같으며, "||"는 OR 연산자와 같다. set sql_mode = 'PIPES_AS_CONCAT'; 추가시 "||" 는 concat 연산자로 작동한다. "&&" 연산자는 그대로 작동한다.
set sql_mode = 'PIPES_AS_CONCAT';
select 'abc'||'def' as concated_string, 1 && 0 , 1 and 0, 1 or 0, 1||0;
5) 나누기(/, DIV)와 나머지(%, MOD) 연산자
나누기 연산자로 / 는 몫의 정수값과 소수값을 전부 반환한다. 나눈 몫의 정수 부분만 가져오려면 DIV연산자를 사용한다. 나머지를 가져오는 연산자로 %, MOD를 사용한다.
select 25/4, 25 div 4, mod(25,4), 25 mod 4, 25 % 4 ;
6) REGEXP 연산자
문자열 값이 어떤 패턴을 만족하는지 확인하는 연산자이며, RLIKE는 REGEXP와 똑같은 비교를 수행하는 연산자다. RLIKE는 가끔 문자열 값의 오른쪽 일치용 LIKE 연산자(Right LIKE)로 혼동할 때가 있는데, MySQL의 RLIKE는 정규 표현식(Regular expression)을 비교하는 연산자다.
REGEXP 연산자의 정규 표현식은 POSIX 표준으로 구현돼 있어서 POSIX 정규 표현식에서 사용하는 패턴 키워드를 그대로 사용할 수 있다.
select 'abc' regexp '^[x-z]', 'abc' regexp '^[bc]', 'abc' regexp '^[a]';
REGEXP 연산자를 문자열 컬럼 비교에 사용할 때 REGEXP 조건의 비교는 인덱스 레인지 스캔을 사용할 수 없다. 따라서 WHERE 조건절에 REGEXP 연산자를 사용한 조건을 단독으로 사용하는 것은 성능상 좋지 않다. 가능한 범위를 줄일 수 있는 조건과 함께 REGEXP 연산자를 사용하길 권장한다.


select regexp_substr('1a','[0-9][a-z]'); -- 1a
select regexp_substr('9z','[0-9][a-z]'); -- 9z
select regexp_substr('aA','[^0-9][A-Z]'); -- aA
select regexp_substr('aA','[^0-9][^a-z]'); -- NULL => 대소문자 구별 안한다.
select regexp_substr('Aa','[^0-9][^a-z]'); -- NULL => 대소문자 구별 안한다.
7) LIKE 연산자
REGEXP 연산자는 인덱스를 전혀 사용하지 못한다는 단점이 있지만, LIKE 연산자는 인덱스를 이용해 처리할 수도 있다. LIKE연산자는 어떤 상수 문자열이 있는지 없는지를 판단한다.
select 'abcdef' like 'abc%' -- 1
, 'abcdef' like '%abc' -- 0
, 'abcdef' like '%ef' -- 1
, 'abcdef' like 'abc_ef'; -- 1
% : 0 또는 1개 이상의 모든 문자에 일치
_ : 정확히 1개의 문자에 일치
와일드카드 문자인 '%' 나 '_' 문자 자체를 비교한다면 ESCAPE절을 LIKE 조건 뒤에 추가해 설정할 수 있다.
select 'abc' like 'a/%' escape '/'; -- 0
select 'a%' like 'a/%' escape '/'; -- 1
LIKE 연산자는 와일드카드 문자인 (%,_)가 검색어의 뒤쪽에 있다면 인덱스 레인지 스캔으로 사용할 수 있지만 와일드 카드가 검색어의 앞쪽에 있다면 인덱스 레인지 스캔을 사용할 수 없다.
"rstian"으로 끝나는 이름을 검색할 때는 와일드카드가 검색어의 앞쪽에 있으면 인덱스의 left-most 특성으로 인덱스 레인지 스캔을 사용하지 못하고 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔 방식으로 쿼리가 처리됨을 알 수 있다.
explain
select count(*)
from employees where first_name like '%rstian';
type 의 index 는 index full scan을 의미한다.
8) BETWEEN 연산자
BETWEEN 연산자는 "크거나 같다"와 "작거나 같다"라는 두 개의 연산자를 하나로 합친 연산자다.
BETWEEN는 범위를 읽어야 하는 연산자라서 뒤에 동등조건이 오더라도 엑세스 조건으로 사용되지 못한다.
-- 두 조건 모두 인덱스를 이용해 범위를 줄여줄 수 있다.(인덱스 엑세스 조건 : dept_no, emp_no)
select * from dept_emp where dept_no = 'd003' and emp_no = 10001;
-- dept_no만 인덱스를 이용해 범위를 줄여줄 수 있다.(인덱스 엑세스 조건 : dept_no)
select * from dept_emp where dept_no between 'd003' and 'd005' and emp_no = 10001;
-- 두 조건 모두 인덱스를 이용해 범위를 줄여줄 수 있다.(인덱스 엑세스 조건 : dept_no, emp_no)
select * from dept_emp where dept_no in ('d003', 'd004', 'd005') and emp_no = 10001;
9) IN 연산자
IN은 여러 개의 값에 대해 동등 비교 연산을 수행하는 연산자다. 여러 개의 값이 비교되지만 범위로 검색하는 것이 아니라 여러 번의 동등 비교로 실행하기 때문에 일반적으로 빠르게 처리된다.
IN 연산자를 이용해 NULL 값을 검색할 수는 없다. 값이 NULL인 레코드를 검색하려면 NULL-Safe 연산자인 "<=>" 또는 IS NULL 연산자 등을 사용해야 한다. (MySQL8.0.20 에서 index range scan을 한다.)
select * from employees where emp_no in (10001,10002,null);

select * from employees where first_name in ('Georgi','Bezalel', null);
NOT IN의 실행 계획은 인덱스 풀 스캔으로 표시되는데, 동등이 아닌 부정형 비교라서 인덱스를 이용해 처리 범위를 줄이는 조건으로는 사용할 수 없기 때문이다.
NOT IN 연산자가 Primary Key와 비교될 때 가끔 쿼리의 실행 계획의 인덱스 레인지 스캔으로 표시될 수도 있다. 하지만 이는 InnoDB 테이블에서 Primary Key가 클러스터링 키이기 때문일 뿐 실제 IN과 같이 효율적으로 실행된다는 것을 의미하지는 않는다.
explain select * from employees where first_name not in ('Georgi','Bezalel');
explain select * from employees where first_name not in ('Georgi','Bezalel');
3. MySQL 내장 함수
MySQL의 함수는 MySQL에서 기본적으로 제공하는 내장 함수와 사용자가 직접 작성해서 추가할 수 있는 사용자 정의 함수( UDF)로 구분된다. MySQL에서 제공하는 C/C++ API를 이용해 사용자가 원하는 기능을 직접 함수로 만들어 추가할 수 있는데 이를 사용자 정의 함수라고 한다. 여기서 언급하는 내장 함수나 사용자 정의 함수는 스토어드 프로그램으로 작성되는 프로시저나 스토어드 함수와는 다르므로 혼동되지 않도록 주의하자.
1) NULL 값 비교 및 대체 (IFNULL, ISNULL)
IFNULL(첫 번째 인자, 두 번째 인자) 함수의 반환 값은 첫 번째 인자가 NULL이 아니면 첫 번째 인자의 값을, 첫 번째 인자의 값이 NULL이면 두 번째 인자의 값을 반환한다.
ISNULL(표현식) 함수는 인자의 표현식이 NULL이면 TRUE(1), NULL이 아니면 FALSE(0)을 반환한다.
select ifnull(null, 1), ifnull('abc', 1), isnull('abc'), isnull(1/0), isnull(null);
2) 현재 시각 조회 (NOW, SYSDATE)
하나의 SQL에서 NOW()함수는 같은 값을 가지고 SYSDAT() 함수는 하나의 SQL 내에서도 호출되는 시점에 따라 결과 값이 달라진다.
select now(), sleep(2), now();
select sysdate(), sleep(2), sysdate();
NOW()함수는 호출되는 시점의 시간을 반환하지만 SYSDATE() 함수는 Sleep() 함수의 대기 시간인 2초 동안의 차이가 있음을 알 수 있다.
[SYSDATE() 함수의 특성으로 인한 문제]
- SYSDATE() 함수가 사용된 SQL은 복제가 구축된 MySQL의 슬레이브에서 안정적으로 복제(Replication)되지 못한다.
- SYSDATE() 함수와 비교되는 컬럼은 인덱스를 효율적으로 사용하지 못한다.
[SYSDATE() 함수 인덱스 사용 예제]
salaries Table PK : emp_no + from_date
emp_no+from_date 인덱스 사용 => key_len : 7bytes
explain
select emp_no, salary, from_date, to_date
from salaries where emp_no=10001 and from_date>now();
emp_no+from_date 인덱스 사용 => key_len : 4bytes, emp_no만 사용
explain
select emp_no, salary, from_date, to_date
from salaries where emp_no=10001 and from_date>sysdate();
SYSDATE() 함수는 호출될 때마다 다른 값을 반환하므로 사실은 상수가 아니다. 그래서 인덱스를 스캔할 때도 매번 비교되는 레코드마다 함수를 실행해야만 한다. 하지만 NOW() 함수는 쿼리가 실행되는 시점에서 값을 할당받아서 그 값을 SQL문장의 모든 부분에서 사용하기 때문에 쿼리가 1시간 동안 실행되더라도 실행되는 위치나 시점에 관계없이 항상 같은 값을 가진다.
MySQL 서버의 설정 파일(my.cnf나 my.ini 파일)에 sysdate-is-no 를 설정하면 sysdate() 함수도 now() 함수와 같이 함수의 호출 시점에 관계없이 하나의 SQL에서는 같은 값을 갖게 설정해야 한다.
3) 날짜와 시간의 포맷 (DATE_FORMAT, STR_TO_DATE)
DATE_FORMAT() 함수는 DATETIME 타입의 컬럼이나 값을 원하는 형태의 문자열로 변환한다.

select date_format(now(), '%Y-%m-%d') as current_dt ;
select date_format(now(), '%Y-%m-%d %H:%i:%s') as current_dttm;
SQL에서 표준형태(년-월-일 시:분:초)로 입력된 문자열은 필요한 경우 자동으로 DATETIME타입으로 변환되어 처리된다. 또한 STR_TO_DATE() 함수를 이용해 문자열을 DATETIME 타입으로 변환할 수 있다.
select str_to_date('2021-02-01', '%Y-%m-%d') as current_dt;
select str_to_date('2021-02-01 10:11:27', '%Y-%m-%d %H:%i:%s') as current_dttm;
4) 날짜와 시간의 연산 (DATE_ADD, DATE_SUB)
특정 날짜에서 년도나 월일 또는 시간등을 더하거나 뺄 때는 DATE_ADD() 함수나 DATE_SUB() 함수를 이용한다.
DATE_ADD() 함수로 더하거나 빼는 처리를 모두 할 수 있다. 두 함수는 두개의 인자를 받는다. 첫 번째 인자는 연산을 수행할 날자이며, 두 번째 인자는 INTERVAL n [YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, QUARTER, WEEK] 형태로 입력해야 한다.
select date_add(now(), interval 1 day) as tomorrow;
select date_add(now(), interval -1 day) as yesterday;
5) 타임 스탬프 연산 (UNIX_TIMESTAMP, FROM_UNIXTIME)
UNIX_TIMESTAMP() 함수는 '1970-01-01 00:00:00' 을 기준으로 경과된 초의 수를 반환하는 함수다. UNIX_TIMESTAMP() 함수는 인자가 없으면 현재 날짜와 시간의 타임스탬프 값을, 인자로 특정 날짜를 전달하면 그 날짜와 시간의 타임스탬프를 반환한다. FROM_UNIXTIME()함수는 UNIX_TIMESTAMP() 함수와 반대로, 인자로 전달한 타임스탬프 값을 DATETIME 타입으로 변환하는 함수다.
select UNIX_TIMESTAMP('2020-02-01 18:15:08')
, FROM_UNIXTIME(UNIX_TIMESTAMP('2020-02-01 18:15:08')) ;
MySQL의 TIMESTAMP 타입은 4바이트 숫자 타입으로 저장되기 때문에 실제로 가질 수 있는 값의 범위는 '1970-01-01 00:00:01' ~ 2038-01-19 03:14:07' UTC 까지의 날짜 값만 가능하다.
MySQL TIME ZONE 조회는 아래와 같이 한다. 자세한 내용은 documentation 참조.
select @@global.time_zone, @@session.time_zone ;
-- session time zone 변경
SET @@time_zone = 'SYSTEM';
SET @@time_zone = '+00:00';
6) 문자열 처리 (RPAD, LPAD /RTRIM, LTRIM, TRIM)
LPAD(), RPAD() 함수는 문자열의 좌우측에 지정된 길이의 나머지 문자를 3번째 인자로 채워서 문자열을 만든다.
select RPAD('RPAD',10,'0'), LPAD('LPAD',10,'0') ;
RTRIM(), LTRIM() 함수는 문자열의 좌우측에 연속된 공백 문자(Space, NewLine, Tab 문자)를 제거하는 함수다. TRIM()함수는 좌우측 끝의 연속된 공백문자를 제거한다.
select replace(RTRIM(' RTRIM '),' ','*'), replace(LTRIM(' LTRIM '),' ','*'),replace(TRIM(' TRIM '),' ','*')
7) 문자열 결합 (CONCAT)
문자열을 연결해서 하나의 문자열로 반환하는 함수로, 인자의 개수는 제한이 없다. 숫자 값을 인자로 전달하면 문자열 타입으로 자동 변환한 후 연결한다.
select CONCAT('abc','efg',123,CAST(4 AS CHAR)) ;
select CONCAT_WS('-','abc','efg','hij');
8) GROUP BY 문자열 결합 (GROUP_CONCAT)
COUNT()나 MAX(), MIN(), AVG()등과 같은 그룹함수(Aggregate, 여러 레코드의 값을 병합해서 하나의 값을 만들어내는 함수) 중 하나다. 주로 GROUP BY와 함께 사용하며, GROUP BY가 없는 SQL에서 사용하면 단 하나의 결과 값만 만들어낸다. GROUP_CONCAT()함수는 값들을 정렬, 구분자 설정, 중복 제거를 하고 연결하는 것도 가능하다.
select group_concat(dept_no) from departments;
select group_concat(dept_no separator '-') from departments;
select group_concat(dept_no order by dept_no desc) from departments;
select group_concat(distinct dept_no order by dept_no desc) from departments;
GROUP_CONCAT() 함수는 지정한 컬럼의 값들을 연결하기 위해 제한적인 메모리 버퍼 공간을 사용한다. GROUP_CONCAT() 함수가 JDBC로 실행 될 때는 경고가 아니라 에러로 취급되어 SQLException이 발생하므로 GROUP_CONCAT()의 결과가 지정된 버퍼 크기를 초과하지 않도록 주의해야 한다.
GROUP_CONCAT() 함수가 사용하는 메모리 버퍼의 크기는 group_concat_max_len 시스템 변수로 조정할 수 있다. 기본으로 설정된 버퍼의 크기가 1KB밖에 안되기 때문에 GROUP_CONCAT() 함수를 자주 사용한다면 버퍼의 크기를 적절히 늘려서 설정하는 것을 고려해야 한다.
show variables like 'group_concat_max_len';
9) 값의 비교와 대체 (CASE WHEN .. THEN .. END)
CASE WHEN 구문을 이용하여 서브쿼리를 실행할 수도 있다.
select e.emp_no, e.first_name, e.gender
,case when e.gender='F' then
(select s.salary from salaries s where s.emp_no = e.emp_no order by from_date desc limit 1)
else 0
end as last_salary
from employees e
order by hire_date desc
limit 10;
10) 타입의 변환 (CAST, CONVERT)
Prepared Statements를 제외하고 SQL은 텍스트(문자열) 기반으로 작동하기 때문에 SQL에 포함된 모든 입력 값은 문자열처럼 취급한다. 이럴 때 명시적으로 타입의 변환이 필요하다면 CAST() 함수를 이용한다.
CAST함수를 통해 변환할 수 있는 데이터 타입은 DATE, TIME, DATETIME, BINARY, CHAR, DECIMAL, SIGNED INTEGER, UNSIGNED INTEGER이다.
select CAST('1234' as SIGNED INTEGER) as converted_integer;
select CONVERT('1234' , SIGNED INTEGER) as converted_integer;
select CAST('2021-02-01' as DATE) AS converted_date;
select CONVERT('2021-02-01', DATE) as converted_date;
일반적으로 문자열과 숫자 그리고 날짜의 변환은 명시적으로 해주지 않아도 MySQL이 자동으로 필요한 형태로 변환하는 경우가 많다. 하지만 SIGNED나 UNSIGNED와 같은 부호 있는 정수 또는 부호 없는 정수 값의 변환은 그렇지 않을 때가 많아 명시적인 타입 변환을 할 필요가 있다.
select 1-2, cast(1-2 as unsigned);
select 1-2, CONVERT(1-2 , unsigned);
CONVERT 함수는 CAST 함수와 같이 타입을 변환하는 용도와 문자열의 문자집합을 변환하는 용도라는 두 가지로 사용할 수 있다.
select convert('ABC' USING 'utf8') ;
11) 이진값과 16진수 (Hex String) 문자열 변환 (HEX, UNHEX)
HEX 함수는 이진값을 사람이 읽을 수 있는 16진수의 문자열(Hex string)로 변환하는 함수이고, UNHEX 함수는 16진수 문자열을 읽어서 이진값(BINARY)으로 변환하는 함수이다.
12) 암호화 및 해시 함수 (MD5, SHA)
MD5와 SHA 모두 비대칭형 암호화 알고리즘인데, 인자로 전달한 문자열을 각각 지정된 비트 수의 해시 값을 만들어내는 함수다. SHA 함수는 SHA-1 암호화 알고리즘을 사용하며, 결과로 160비트(20bytes) 해시 값을 반환한다. MD5는 메시지 다이제스트(Message Digest) 알고리즘을 사용해 128비트(16bytes) 해시 값을 반환한다.
두 함수 모두 사용자의 비밀번호와 같은 암호화가 필요한 정보를 인코딩하는 데 사용되며, 특히 MD5 함수는 말 그대로 입력된 문자열(Message)의 길이를 줄이는(Digest) 용도로도 사용된다. 두 함수의 출력 값은 16진수로 표시되기 때문에 저장하려면 저장 공간이 각각 20Bytes와 16Bytes의 두 배씩 필요하다. 암호화된 값을 저장해 두기 위해 MD5 함수는 CHAR(32), SHA 함수는 CHAR(40)의 타입을 필요로 한다.
select md5('abc');
select sha('abc');
저장 공간을 16Bytes, 20Bytes로 줄이고 싶다면 BINARY형태의 타입에 저장하면 된다. 컬럼의 타입을 BINARY(16), BINARY(20)으로 정의하고 MD5 함수나 SHA 함수의 결과를 UNHEX 함수를 이용해 이진값으로 변환해서 저장하면 된다. BINARY 타입에 저장된 이진값을 사람이 읽을 수 있는 16진수 문자열로 되돌릴 때는 HEX 함수를 사용한다.
create table tab_binary(col_md5 binary(16), col_sha binary(20));
insert into tab_binary values(unhex(md5('abc')), unhex(sha('abc')));
select hex(col_md5), hex(col_sha) from tab_binary;
MD5, SHA함수는 비대칭형 암호화 알고리즘이다. 이 두 함수의 결과 값은 중복 가능성이 매우 낮기 때문에 길이가 긴 데이터를 크기를 줄여서 인덱싱(해시)하는 용도로도 사용된다. 예를 들어 URL과 같은 값은 1KB를 넘을 때도 있으며 전체적으로 값의 길이가 긴 편이다. 이러한 데이터를 검색하려면 인덱스가 필요하지만, 긴 컬럼에 대해 전체값으로 인덱스를 생성하는 것은 불가능(Prefix 인덱스 제외)할 뿐더러 공간 낭비도 커진다. URL의 값을 MD5() 함수로 단축하면 16Bytes로 저장할 수 있고 16Bytes로 인덱스를 생성하면 되기 때문에 상대적으로 효율적이다.
13) 처리 대기 (SLEEP)
SLEEP 함수는 프로그래밍 언어나 쉘 스크립트 언어에서 제공하는 "sleep" 기능을 수행한다.
select sleep(2)
from employees
where emp_no between 100001 and 100003;
SLEEP 함수는 레코드 건수만큼 SLEEP 함수를 호출하기 때문에 위 쿼리는 3*2초=6초 동안 쿼리를 실행한다.
14) 벤치마크 (BENCHMARK)
BENCHMARK 함수는 SLEEP 함수와 같이 디버깅이나 간단한 함수의 성능 테스트용으로 아주 유용한 함수다. BENCHMARK 함수는 2개의 인자를 필요로 한다. 첫 번째 인자는 반복해서 수행할 횟수이며, 두 번째 인자로는 반복해서 실행할 표현식을 입력하면 된다. 두 번째 인자의 표현식은 반드시 스칼라 값을 반환하는 표현식이어야 한다. 즉 SELECT 쿼리를 BENCHMARK 함수에 사용하는 것도 가능하지만 반드시 스칼라 값(하나의 컬럼을 가진 하나의 레코드)만 반환하는 SELECT 쿼리만 사용할 수 있다.
BENCHMARK 함수의 반환값은 중요하지 않으며, 단지 지정한 횟수만큼 반복 실행하는 데 얼마나 시간이 소요됐는지가 중요할 뿐이다.
[MD5 함수를 10만번 실행 0.04초 소요시간 확인]
select benchmark(100000, md5('abcdefghijk'));
[employees 테이블에서 건수만 세는 SQL의 성능 확인]
select benchmark(100,(select count(*) from employees));
"SELECT BENCHMARK(10, expr)"와 "SELECT expr"을 10번 직접 실행하는 것과는 차이가 있다. 직접 실행한느 경우에는 매번 쿼리의 파싱이나 최적화, 테이블 락이나 네트워크 비용 등이 소요된다. 하지만 "SELECT BENCHMARK(10,expr)" 로 실행하는 경우에는 벤치마크 횟수에 관계없이 단 1번의 네트워크, 쿼리파싱 및 최적화 비용이 소요된다는 점을 고려해야 한다. 또한 "SELECT BENCHMARK(10,expr)"를 사용하면 한 번의 요청으로 expr 표현식이 10번 실행되는 것이므로 이미 할당받은 메모리 자원까지 공유되고, 메모리 할당도 직접 "SELECT expr" 쿼리로 10번 실행하는 것보다 1/10밖에 일어나지 않는다. BENCHMARK 함수로 얻은 쿼리나 함수의 성능은 그 자체로는 별로 의미가 없으며, 두 개의 동일 기능을 상대적으로 비교 분석하는 용도로 사용할 것을 권장한다.
15) IP 주소 변환 (INET_ATON, INET_NTOA)
IP주소는 4Bytes의 부호 없는 정수(Unsigned integer)이다. IP정보를 VARCHAR(15) 타입에 '.'으로 구분해서 저장하면 저장공간을 훨씬 많이 필요로 한다. 일반적으로 IP 주소를 저장할 때 "127.0.0.1" 형태로 저장하므로 IP 주소 자체를 A, B, C 클래스로 구분하는 것도 불가능하다.
MySQL에서는 INET_ATON 함수와 INET_NTOA 함수를 이용해 IP주소를 문자열이 아닌 부호 없는 정수 타입(UNSIGED INTEGER)에 저장할 수 있게 제공한다. INET_ATON 함수는 문자열로 구성된 IP 주소를 정수형으로 변환하는 함수이며, INET_NTOA 함수는 정수형의 IP 주소를 '.'로 구분된 문자열로 변환하는 함수이다.
아래 예제는 IP주소를 UNSIGNED INTEGER 타입에 저장하고, '127.0.0.128' ~ '127.0.0.255' 사이의 IP로부터 접근했던 이력만 조회해 보는 과정을 통해 어떻게 IP 주소를 저장하고 검색할 수 있는지 보여준다.
create table tab_accesslog(access_dttm DATETIME, ip_addr INTEGER UNSIGNED);
insert into tab_accesslog values(now(), inet_aton('127.0.0.130'));
select * from tab_accesslog;
select access_dttm, inet_ntoa(ip_addr) as ip_addr
from tab_accesslog
where ip_addr between inet_aton('127.0.0.128') and inet_aton('127.0.0.255');
16) MySQL 전용 암호화 (PASSWORD, OLD_PASSWORD)
현재 사용하는 MySQL버전은 5 이상이므로 신경 쓰지 않아도 된다.
[PASSWORD 함수의 변화]
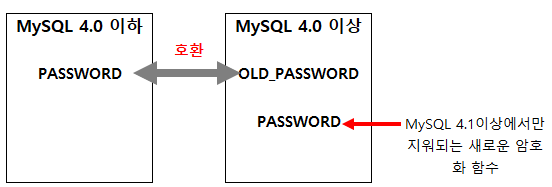
MySQL의 PASSWORD() 함수는 MySQL DBMS 유저의 비밀번호를 관리하기 위한 함수이다.
일반 서비스의 고객 정보를 암호화하기 위한 용도로는 MD5, SHA 함수를 이용하는 것을 권장한다.
17) VALUES()
이 함수는 INSERT INTO ... ON DUPLICATE KEY UPDATE ... 형태의 SQL문장에서만 사용할 수 있다.
Primary Key나 Unique Key가 중복되는 경우에는 UPDATE를 수행하고, 그렇지 않으면 INSERT를 수행하는 문장이다.
create table tb_stat(emp_no int, visit_count int, primary key(emp_no));
insert into tb_stat values (1, 1), (2, 2);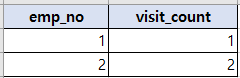
create table tb_access(emp_no int, visit_date datetime, primary key(emp_no, visit_date));
insert into tb_access values (1, now());
insert into tb_access values (1, now());
insert into tb_access values (1, now());
insert into tb_access values (1, now());
insert into tb_access values (1, now());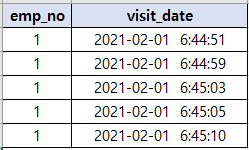
insert into tb_stat(emp_no, visit_count)
select emp_no, count(*) as cnt
from tb_access
group by emp_no
on DUPLICATE KEY
UPDATE visit_count = visit_count + values(visit_count);
-- update절에서 values() 함수를 이용해 해당 컬럼에 insert 하려고 했던 값을 참조
-- values 함수의 인자값으로는 INSERT 문장에서 값을 저장하려고 했던 컬럼의 이름을 입력하면 된다.
select * from tb_stat;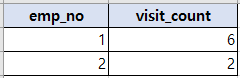
18) COUNT()
COUNT 함수는 레코드 건수를 반환하는 함수로 '*'는 SELECT 절에 사용된 모든 컬럼을 가져오라는 것이 아니라 레코드 자체를 의미한다. 그래서 COUNT(1)과 COUNT(*)는 같은 속도로 처리된다
MyISAM 스토리지 엔진을 사용하는 테이블은 항상 테이블의 메타 정보에 전체 레코드 건수를 관리한다. WHERE절이 없는 COUNT(*) 쿼리의 결과는 바로 반환 된다.
인덱스를 제대로 사용하도록 튜닝하지 못한 COUNT(*) 쿼리는 페이징해서 데이터를 가져오는 쿼리보다 몇 배에서 몇 십배까지 느릴 수 있으므로 주의 깊게 작성해야 한다.
COUNT 함수는 컬럼명이나 표현식이 인자로 사용되면 인자의 결과가 NULL이 아닌 레코드 건수만 반환하므로 NULL이 포함된 컬럼이나 표현식을 사용할 때 의도대로 쿼리가 작동하는지 확인하는 것이 필요하다.
4. SQL 주석
-- 이 표기법은 한 라인만 주석으로 처리합니다.
/* 이 표기법은 여러 라인을
주석으로 처리합니다. */
/*!로 시작하는 주석은 선별적으로 기능이나 옵션을 적용하게 할 수 있다. 아래 예제는 /*! 주석 표기 뒤에 5자리 숫자가 나열되어 있다. MySQL 버전은 메이저 버전을 나타내는 1글자와 마이너 버전을 나타내는 2글자 그리고 패치버전으로 2글자를 사용해서 5글자의 숫자로 구성된다. 아래 주석 문장은 MySQL 버전에 따라 주석이 될수도 있고 실제 쿼리 문장의 일부가 될 수도 있다.
drop table tb_test;
create /*!50154 temporary */ table tb_test(fd int, primary key(fd));
-- MySQL 5.1.54 이상
create temporary table tb_test(fd int, primary key(fd));
-- MySQL 5.1.54 미만
create table tb_test(fd int, primary key(fd));
show create table tb_test;
CREATE TEMPORARY TABLE `tb_test` (
`fd` int NOT NULL,
PRIMARY KEY (`fd`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
MySQL 5.1.54 이상에서는 임시 테이블을 생성하고, 그 이하 버전에서는 일반 테이블을 생성한다. MySQL5.0에서 쿼리나 프로시저에 포함된 주석은 모두 삭제 되기도 하는데 스토어드 프로그램의 코드에 주석을 추가할때 기준 버전을 최댓값으로 설정애두면 MySQL은 항상 주석으로만 인식하지만 삭제하지는 않게 된다.
create function sf_getstring()
returns varchar(20) character set utf9
begin
/*!99999 이 함수는 문자집합 테스트용 프로그램임 */
return '한글 테스트';
end;;
'MySQL > MySQL' 카테고리의 다른 글
| DISTINCT (0) | 2024.12.09 |
|---|---|
| SELECT문 (0) | 2024.12.09 |
| 쿼리와 연관된 시스템 설정 (0) | 2024.12.06 |
| MySQL의 주요 처리방식 (0) | 2024.12.06 |
| 실행계획 분석시 주의 사항 (0) | 2024.12.06 |