MySQL 실행계획 분석
1.ID
select 문장은 하나인데 여러개의 테이블이 조인되는 경우에는 ID값이 증가하지 않고 같은 ID를 부여한다.
2. select_type 컬럼
각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 컬럼이다.
2-1. SIMPLE
UNION이나 서브 쿼리를 사용하지 않는 단순한 SELECT쿼리인 경우, 해당 쿼리 문장의 select_type은 SIMPLIE로 표시
2-2. PRIMARY
UNON이나 서브쿼리가 포함단 쿼리의 실행 계획에서 가장 outer에 있는 단위 쿼리는 Primary로 표시된다.
2-3. UNION
UNION으로 결합하는 쿼리의 첫 번째를 제외한 두 번째 이후 단위 쿼리의 select_type은 UNION으로 표시된다.
2-4. DEPENDENT UNION
UNION, UNION ALL로 결합된 단위 쿼리가 외부의 영향을 받는 것을 의미한다.
2-4. UNION RESULT
UNION 결과를 담아두는 테이블을 의미한다. MySQL에서 UNON ALL이나 UNION(DISTINCT) 쿼리의 결과는 임시테이블로 생성한다. 실행계획에서 이 임시테이블을 가리키는 라인의 select type이 UNION RESULT이다.
UNION RESULT는 실제 쿼리에서 단위 쿼리가 아니기 때문에 별도로 id값을 부여하지 않는다.
2-5. SUBQUERY(서브쿼리)
여기서 SUBQUERY라고 하는 것은 From절 이외에서 사용되는 서브 쿼리만을 의미한다.
1). 서브쿼리의 사용 위치에 따른 구별
- Nested Query(중첩된 쿼리) : SELECT List에 사용된 서브쿼리
- Sub Query(서브 쿼리) : WHERE 절에 사용된 경우
- Derived(파생 테이블) : From 절에 사용된 서브 쿼리
2). 서브쿼리가 반환하는 값의 특성에 따른 구분
- Scalar SubQuery(스칼라 서브 쿼리) : 하나의 값만 반환하는 쿼리
- Row SubQuery(로우 서브 쿼리) : 컬럼의 개수에 관계없이 하나의 레코드만 반환하는 쿼리
2-6. DEPENDENT SUBQUERY
서브 쿼리가 OUTER 쿼리에서 정의된 컬럼을 사용하는 경우 inner 서브쿼리가 outer 쿼리의 컬럼에 의존적이라서 Dependent라는 키워드가 붙는다. 또한 outer쿼리가 실행된 후 inner쿼리가 실행돼야 하므로 일반 서브 쿼리보다는 처리 속도가 느릴 때가 많다.
2-7. DERIVED
서브쿼리가 FROM절에 사용된 경우 select_type=DERIVED인 실행계획 이다. Derived는 단위 SELECT의 결과를 메모리나 디스크에 임시 테이블(파생 테이블)을 생성 한다. Derived 서브쿼리의 파생테이블은 인덱스가 전혀 없으므로 다른 테이블과 조인시 성능상 불리 하다. MySQL6.0이상 버전부터는 From절의 서브쿼리에 대한 최적화 부분이 개선 예정이다. 자신이 사용하는 버전의 FROM절의 실행계획을 확인할 필요가 있다.
[MySQL8.0] 에서 아래 쿼리는 select_type이 Derived가 아니다 -> 최적화
EXPLAIN
SELECT *
FROM (SELECT de.emp_no FROM dept_emp de) tb
, employees e
WHERE e.emp_no = tb.emp_no;
2-9. UNCACHEABLE SUBQUERY
서브쿼리의 결과를 내부적인 캐시 공간에 담아두는 서브쿼리캐시
- SubQuery는 바깥쪽(Outer)의 영향을 받지 않고 처음 한 번만 실행해서 그 결과를 캐시하고 필요할 때 캐시된 결과를 이용한다.
- Dependent SubQuery는 의존하는 Outer 쿼리의 컬럼의 값 단위로 캐시해두고 사용한다.
[캐시를 사용하지 못하는 요소]
1) 사용자 변수가 서브 쿼리에 사용된 경우
2) NOT-DETERMINISTIC 속성의 스토어드 루틴이 서브쿼리 내에 사용된 경우
3) UUID()나 RAND()와 같이 결과값이 호출할 때마다 달라지는 함수가 서브 쿼리에 사용된 경우
[MySQL8.0]
EXPLAIN
SELECT *
FROM employees e
WHERE e.emp_no = (SELECT @status FROM dept_emp de WHERE de.dept_no='d005')
;|
id
|
select_type
|
table
|
type
|
possible_keys
|
key
|
key_len
|
ref
|
rows
|
filtered
|
Extra
|
|
1
|
PRIMARY
|
e
|
ALL
|
|
|
|
|
299645
|
100
|
Using where
|
|
2
|
UNCACHEABLE SUBQUERY
|
de
|
ref
|
PRIMARY,ix_fromdate,ix_empno_fromdate
|
PRIMARY
|
16
|
const
|
165571
|
100
|
Using where; Using index
|
2-10. UNCACHEABLE UNION
union 쿼리가 사용자변수나 UUID()같은 함수를 사용하여 UNCACHEABLE할 때 SELECT_TYPE에 표시된다.
3. TABLE 컬럼
MySQL의 실행 계획은 단위 SELECT 쿼리 기준이 아니라 테이블 기준으로 표시된다. 만약 테이블의 이름에 별칭이 부여된 경우에는 별칭이 표시된다. 별도의 테이블을 사용하지 않는 select 쿼리의 경우에는 NULL로 표시된다.
explain select now();
-- --------------------
ID SELECT_TYPE TABLE
1 SIMPLE NULL
-- --------------------
MySQL은 FROM절에 사용된 서브쿼리(Derived, 파생테이블)는 반드시 별칭을 가져야 한다.
select dttm from (select now() as dttm) ;
-----------------------------------------------------------------------
SQL Error [1248] [42000]: Every derived table must have its own alias
-----------------------------------------------------------------------
select dttm from (select now() as dttm) derived_table_alias ;
-----------------------------------------------------
DTTM
2021-01-09 19:48:10
-----------------------------------------------------
실행계획 분석 예제)
Table 컬럼에 <derived> 또는 <union>과 같이 "<>"로 둘러싸인 경우 이 테이블은 임시 테이블을 의미한다. 또한 "<>" 안에 항상 표시되는 숫자는 단위 SELECT 쿼리의 id를 지칭한다.
|
id
|
select_type
|
table
|
type
|
Key
|
key_len
|
ref
|
rows
|
|
1
|
PRIMARY
|
<derived2>
|
ALL
|
10420
|
|||
|
1
|
PRIMARY
|
e
|
eq_ref
|
PRIMARY
|
4
|
de1.emp_no
|
1
|
|
2
|
DERIVED
|
dept_emp
|
range
|
ix_fromdate
|
3
|
20550
|
<defived2> = id가 2인 dept_emp 테이블로부터 select된 결과가 저장된 파생 테이블이다
1) 첫 번째 라인의 테이블이 <derived2>라는 것으로 보아 이라인보다 쿼리의 id가 2번인 라인이 먼저 실행되고 그 결과가 파생 테이블로 준비돼야 한다
2) 세 번째 라인의 쿼리 id 2번을 보면, select_type의 컬럼 값이 derived로 표시되어 있다. 즉, dept_emp테이블을 읽어서 파생테이블을 생성한다.
3) 세 번째 라인의 분석이 끝났으므로 다시 실행 계획의 첫 번째 라인으로 돌아가자
4) 첫 번째 라인과 두 번째 라인은 같은 id 값을 가지고 있으므로 2개의 테이블 <derived2>와 e 테이블은 조인되는 쿼리이다. 선행되는 <derived2>가 드라이빙 테이블이고, e 테이블이 드리븐 테이블이 된다. <derived2> 테이블을 먼저 읽어서 e테이블로 조인이 실행 된다.
4. type 컬럼
실행 계획에서 type 이후의 컬럼은 MySQL서버가 각 테이블의 레코드를 어떤 방식으로 읽었는지를 의미한다.
type컬럼은 각 테이블의 접근 방식(Access type)으로 해석하면 된다.
[type컬럼에 표시될 수 있는 값] MySQL에서 부여한 우선순위로 성능이 빠른 순서대로 나열
|
system
|
const
|
eq_ref
|
ref
|
fulltext
|
ref_or_null
|
|
unique_subquery
|
index_subquery
|
range
|
index_merge
|
index
|
ALL
|
4-1. system
레코드가 1건 or 한건도 존재하지 않는 테이블을 참조하는 접근방법으로 MyISAM이나 MEMORY 테이블에서만 사용되는 접근 방법이다.
explain
select * from tb_dual;|
id
|
select_type
|
table
|
type
|
key
|
key_len
|
rows
|
filtered
|
Extra
|
|
1
|
SIMPLE
|
tb_dual
|
index
|
PRIMARY
|
1
|
1
|
100
|
Using index
|
4-2. const
Primary key or Unique key 컬럼을 이용하는 조건절을 가지고 있어서 반드시 1건을 반환하는 처리방식 이다.
다른 DBMS에서는 UNIQUE INDEX SCAN이라 한다
explain
select * from employees where emp_no = 10001;|
id
|
select_type
|
table
|
type
|
possible_keys
|
key
|
key_len
|
ref
|
rows
|
filtered
|
|
1
|
SIMPLE
|
employees
|
const
|
PRIMARY
|
PRIMARY
|
4
|
const
|
1
|
100
|
다중 키로 구성된 Primary key or Unique key 중에서 인덱스 일부 컬럼만 조건으로 사용할 때는 const 타입의 접근방법을 사용할 수 없다. 실제 레코드가 1건인지 2건이상인지는 데이터를 읽어봐야 알 수 있다.
show index from dept_emp;
primary : dept_no + emp_no
1) Primary Key 일부만 조건으로 사용할 때는 접근 방식이 const가 아닌 ref로 표시된다.
explain
select * from dept_emp where dept_no = 'd005';
2) Primary Key or Unique Index의 모든 컬럼을 동등 조건으로 사용하면 const 접근 방법을 사용한다.
explain
select *
from dept_emp
where dept_no = 'd005'
and emp_no = 10001;
*show index from employees
3) 실행계획의 type컬럼이 const인 실행계획은 쿼리의 최적화 단계에서 모두 상수화 한다.
explain
select count(*)
from employees e1
where first_name in (select first_name from employees e2 where emp_no = 100001);
위 쿼리는 옵티마이저에 의해 최적화 되는 시점에 아래와 같이 변환되어 쿼리 실행기로 전달되기 때문에 접근 방식이 const인 것이다.
select count(*)
from employees e1
where first_name = 'Jasminko';
4-3. eq_ref
테이블이 조인되는 쿼리의 Plan에서 표시 된다. 먼저 읽은 테이블의 컬럼 값을, 나중에 읽어야 할 테이블의 PK이나 Unique key 컬럼의 검색 조건에 사용한다. 뒤에 읽는 테이블을 unique key로 검색할 때 인덱스는 not null이어야 한다. 다중 컬럼으로 만들어진 PK나 유니크 인덱스는 모든 컬럼이 비교 조건에 사용되어야 eq_ref 접근 방법이 사용된다. 즉 조인에서 inner 테이블에서 반드시 1건만 존재한다는 보장이 있어야 사용할 수 있다.
*show index from dept_emp;

explain
select *
from dept_emp de, employees e
where e.emp_no = de.emp_no and de.dept_no ='d005';
조인에서 뒤에오는 employees 테이블의 emp_no는 PK 이어서 실행 계획의 두 번째 라인은 type컬럼이 eq_ref로 표시된 것이다.
4-4. ref
ref 접근 방법은 eq_ref와 달리 조인의 순서와 관계없이 사용되며 인덱스의 종류와 상관없이 Equal조건으로 검색할 때 사용된다. 레코드가 반드시 1건이라는 보장이 없어서 const나 eq_ref보다는 빠르지 않다. 하지만 동등조건으로만 비교 되므로 매우 빠른 조회 방법의 하나이다.
explain
select * from dept_emp where dept_no='d005';
* type = ref 접근방법 , ref = const --> ref 비교 방식으로 사용된 입력 값이 상수('d005')
explain
select * from dept_emp where from_date = '1986-06-26';
* 인덱스 삭제 후 검색하면 ref 접근방법을 사용 못한다. 인덱스 ix_empno_fromdate는 선행조건인 emp_no가 없어서 사용하지 못한다.
drop index ix_fromdate on dept_emp;
explain
select * from dept_emp where from_date = '1986-06-26';
create index ix_fromdate on dept_emp(from_date);
[동등 비교 연산자를 쓰는 접근 방식(type)]
|
const
|
조인의 순서에 관계없이 PK, Unique 인덱스의 모든 컬럼에 대해 동등조건으로 검색(결과 1건)
|
|
eq_ref
|
조인에서 첫 번째 테이블의 컬럼값을 이용하여 두 번째 테이블을 PK, Unique 인덱스로 동증 조건 검색(두 번째 테이블의 결과 1건)
|
|
ref
|
조인의 순서와 인덱스의 종류에 관계없이 동등조건으로 검색(결과 1건이상)
|
동등조건은 "=" 또는 "<=>"을 의미한다. "=" 연산자는 null비교를 못하여 null=null, null=1 의 결과로 null을 반환한다. 하지만 "<=>" 연산자는 null비교를 수행하여 null<=>null 은 1을 null<=>1은 0을 반환한다.
select 1=1, 1<=>1, null=null, null<=>null, null=1, null<=>1 ;
4-5. fulltext
fulltext 접근 방법은 Mysql의 전문 검색(Fulltext) 인덱스를 사용해 레코드를 읽는 접근 방법을 의미한다. 지금 보는 type의 순서가 일반적인 처리 성능의 순서이지만 실제 데이터 분포나 레코드의 건수에 따라 처리 속도가 달라 질 수 있다. 하지만 전문 검색 인덱스는 통계정보가 관리되지 않으며, 전문 검색 인덱스를 사용하려면 전혀 다른 SQL 문법을 사용해야 한다. 그래서 MySQL 옵티마이저는 fulltext 접근 방법 보다 빠른 const나 eq_ref, ref 접근 방법등을 사용할 수 없을 때에 전문 인덱스를 사용할 수 있는 SQL에서는 쿼리의 비용과 관계없이 fulltext 접근 방법을 사용한다.
MySQL에서는 전문 검색 조건은 우선순위가 높다. 쿼리에서 전문인덱스를 사용하는 조건과 일반 인덱스를 사용하는 조건을 함께 사용하면 일반 인덱스의 접근 방법이 const, eq_ref, ref가 아니면 일바적으로 MySQL은 전문 인덱스를 사용하는 조건을 선택해서 처리한다.
*전문 검색(fulltext) 인덱스 사용방법
CREATE TABLE `employee_name` (
`emp_no` int NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
PRIMARY KEY (`emp_no`),
FULLTEXT KEY `fx_name` (`first_name`,`last_name`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
show index from employee_name;
explain
select *
from employee_name
where emp_no=10001 /*PK를 한건만 조회하는 const 타입의 조건*/
and emp_no between 10001 and 10005 /* range 타입의 조건*/
and MATCH(first_name, last_name) AGAINST('Facello' IN BOOLEAN MODE); /*전문검색(FULLTEXT)조건*/
explain
select *
from employee_name
where emp_no between 10001 and 10005
and MATCH(first_name, last_name) AGAINST('Facello' IN BOOLEAN MODE); /*전문검색(FULLTEXT)조건*/
전문 검색 인덱스를 이용하는 fulltext보다 일반 인덱스를 사용하는 range 접근 방법이 더 빨리 처리된느 경우가 많아서 전문 검색 쿼리를 사용할 때는 각 조건별로 성능을 확인해 봐야 한다.
4-6. unique_subquery
where 조건절에서 사용될 수 있는 IN(subquery) 형태의 쿼리를 위한 접근 방식으로 서브쿼리에서 유니크한 값만 반환할 때 사용한다.
실제 Mysql 5.7, 8.0 테스트시 type=unique_subquery 형태의 실행계획 안나온다
explain
select *
from departments
where dept_no in (select dept_no from dept_emp where emp_no = 10001);
4-7. index_subquery
IN (subaquery) or IN (상수나열) 형태의 조건은 괄호 안에 있는 값의 목록에서 중복된 값이 제거돼야 한다. 이때 중복된 값을 인덱스를 이용해 제거할 수 있을 때 index_subquery 접근 방법이 사용된다.
실제 Mysql 5.7, 8.0 테스트시 type=index_subquery 형태의 실행계획 안나온다
explain
select *
from departments
where dept_no in (select dept_no from dept_emp where dept_no between 'd001' and 'd003');
4-8. range
인덱스를 범위로 검색하는 경우를 의미한다 주로 "<, >, IS NULL, BETWEEN, IN, LIKE"등의 연산자를 이용해 인덱스를 검색할 때 사용된다. MySQL이 가지고 있는 접근 방법 중에서 우선순위가 낮지만 빠른 접근 방법 이다.
* 인덱스 레인지 스캔 = const, ref, range 라는 세 가지 접근 방법을 모두 묶어서 지칭한다.
4-9. index_merge
2개 이상의 인덱스를 이용해 각각의 검색 결과를 병합하는 처리 방식이다.
- 여러 인덱스를 읽어야 하므로 range 보다 효율성이 떨어진다.
- AND와 OR 연산이 복잡하게 연결된 쿼리에서는 제대로 최적화 되지 못한다.
- 전문 검색(fulltext) 인덱스를 사용하는 쿼리에서는 index_merge가 적용되지 않는다.
- index_merge 접근 방식으로 처리된 결과는 항상 2개 이상의 집합이 되기 때문에 그 두집합의 교집합ㄴ이나 합집합 또는 중복 제거와 같은 부가적인 작업이 더 필요하다.
explain
select *
from employees
where emp_no between 10001 and 11000
or first_name = 'Smith';
4-10. index
인덱스를 처음부터 끝까지 읽는 INDEX FULL SCAN을 의미한다. 풀 테이블 스캔 방식과 비교했을 때 비교하는 레코드 건수는 같다. 하지만 인덱스는 일반적으로 데이터 파일 전체보다는 크기가 작아서 풀 테이블 스캔보다는 효울적이므로 FULL TABLE SCAN 보다는 빠르게 처리된다. 또한 쿼리의 내용에 따라 정렬된 인덱스의 장점을 이용할 수 있으므로 풀 테이블 스캔보다 효율적일 수도 있다. index 접근 방법은 아래 1),2) 조건 1),3) 조건을 충족한느 쿼리에서 사용되는 읽기 방식이다.
1) range나 const 또는 ref와 같은 접근 방식으로 인덱스를 사용하지 못하는 경우
2) 인덱스에 포함된 컬럼만으로 처리할 수 있는 쿼리인 경우
3) 인덱스를 이용해 정렬이나 그룹핑 작업이 가능한 경우
TABLE_NAME : departments
PRIMARY(dpet_no), ux_deptname(dept_name)
explain
select *
from departments
order by dept_name desc limit 10; /*정렬 처리를 안하고 index full scan*/
explain
select *
from departments
where dept_no > 'd004' /*정렬 처리를 하고 PK 사용*/
order by dept_name desc limit 3;
explain
select *
from departments
where dept_no > 'd004'
order by dept_name desc limit 2; /*정렬 처리를 안하고 index full scan*/
4-11. ALL
Full Table Scan 접근 방식이다. InnoDB에서 Full Table Scan 이나 Index Full Scan과 같은 대량의 디스크 I/O 작업을 위해 한번에 많은 페이지를 읽어 들이는 Read Ahead 기능을 제공한다.
*Read Ahead(리드 어헤드)
MySQL에서는 연속적으로 인접한 페이지가 연속해서 몇 번 읽히게 되면 백그라운드로 작동하는 읽기 스레드가 최대 한 번에 64개의 페이지씩 한꺼번에 디스크로부터 읽어들이기 때문에 한 번에 페이지 하나씩 읽어들이는 작업보다는 상당히 빠르게 레코드를 읽을 수 있다.
5. possible_keys
옵티마이저가 최적의 실행 계획을 만들기 위해 후보로 선정했던 접근 방식에서 사용되는 인덱스의 목록일 뿐이다. 실제로 사용되는 인덱스 목록이 아니기 때문에 possible_keys 컬럼은 무시한다.
6. key
실행 계획에서 사용하는 인덱스를 표시한다. 실행 계획의 type이 ALL일 때와 같이 인덱스를 전혀 사용하지 못하면 Key 컬럼은 NULL로 표시된다.
MySQL에서 Primary key는 별도의 이름을 부여할 수 없으며, 기본적으로 PRIMARY라는 이름을 가진다. 그밖의 나머지 인덱스는 모두 테이블을 생성하거나 인덱스를 생성할 때 이름을 부여할 수 있다. 실행 계획뿐만 아니라 쿼리의 힌트를 사용할 때도 프라이머리 키을 지칭하고 싶다면 PRIMARY라는 키워드를 사용하면 된다.
7. key_len
다중 컬럼으로 구성된 인덱스에서 몇개의 컬럼까지 사용했는지 알려준다. 인덱스의 각 레코드에서 몇 바이트까지 사용했는지 알려주는 값이다.
PRIMARY(dept_no+emp_no)
explain
select * from dept_emp where dept_no = 'd005';

dept_no 컬럼의 타입이 CHAR(4)이기 때문에 프라이머리 키에서 앞족 8byte만 유효하게 사용했다
utf8문자 하나가 차지하는 공간은 1바이트에서 3바이트까지 가변적이지만 MySQL서버가 utf8문자를 위해 메모리 공간을 할당해야 할 때는 문자와 관계없이 고정적으로 3바이트로 계산한다. 여기서 dept_emp는 euckr 문자셋을 사용하여 4*2=8bytes 이다.
* oracle varchar(6) --> 6bytes 할당 , euckr 문자셋(2bytes) 3글자의 한글, utf8 문자셋(1-3bytes) 2글자
* mysql varchar(6) --> 문제셋에 맞춘 6글자 , euckr 6*2= 12bytes 할당, utf8 6*3=18bytes 할당
show collation where charset like 'utf8';
show collation where charset like 'euckr';
* 테이블의 collation 조회
SELECT C.COLLATION_NAME, C.CHARACTER_SET_NAME
FROM INFORMATION_SCHEMA.TABLES T,
INFORMATION_SCHEMA.COLLATION_CHARACTER_SET_APPLICABILITY C
WHERE C.COLLATION_NAME = T.TABLE_COLLATION
AND T.TABLE_SCHEMA = 'EMPLOYEES'
AND T.TABLE_NAME = 'DEPT_EMP';
* 테이블의 collation 컬럼으로 조회
SELECT TABLE_NAME, COLUMN_NAME, COLUMN_TYPE, CHARACTER_SET_NAME, COLUMN_KEY
FROM INFORMATION_SCHEMA.COLUMNS C
WHERE C.TABLE_SCHEMA = 'EMPLOYEES'
AND C.TABLE_NAME = 'DEPT_EMP'
order by ORDINAL_POSITION;
8. ref
접근 방법이 ref 방식일 때 참조 조건(Equal 비교 조건)으로 어떤 값이 제공됐는지 보여 준다. 만약 상수 값을 지정했다면 ref 컬럼의 값은 const로 표시되고, 다른 테이블의 컬럼값이면 그 테이블 명과 컬럼 명이 표시된다.
ref 컬럼의 값이 "func" 라고 표시 될 때가 있다. Function의 줄임말으로 참조용으로 사용되는 값을 그대로 사용한 것이 아니라, 콜레이션 변환이나 값 자체의 연산을 거쳐서 참조됐다는 것을 의미한다.
explain
select *
from employees e, dept_emp de
where e.emp_no = de.emp_no ;

explain
select *
from employees e, dept_emp de
where e.emp_no = (de.emp_no -1) ;

사용자가 명시적으로 값을 변환할 경우와 MySQL 서버가 내부적으로 값을 변환해야 할 때도 ref 컬럼에는 "func"가 출력된다. 문자집합이 일치하지 않는 두 문자열 컬럼을 조인한다거나, 숫자 타입의 컬럼과 문자열 타입의 컬럼으로 조인할 때가 대표적인 예다. 가능하다면 MySQL 서버가 이런 변환을 하지 않도록 조인 컬럼의 타입은 일치시키는 편이 좋다.
*charset 다른 경우 테스트
CREATE TABLE departments_utf8 (
dept_no CHAR(4) NOT NULL,
dept_name VARCHAR(40) NOT NULL,
PRIMARY KEY (dept_no),
UNIQUE KEY (dept_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
insert into departments_utf8 select * from departments;
commit;
[CHARACTER SET 조회]
SELECT TABLE_NAME, COLUMN_NAME, COLUMN_TYPE, CHARACTER_SET_NAME, COLLATION_NAME
FROM INFORMATION_SCHEMA.COLUMNS C
WHERE C.TABLE_SCHEMA = 'EMPLOYEES'
AND C.TABLE_NAME IN ('DEPARTMENTS','DEPARTMENTS_UTF8')
AND C.COLUMN_NAME = 'DEPT_NO'
ORDER BY ORDINAL_POSITION;

explain
select *
from departments d, dept_emp de
where d.dept_no = de.dept_no ;

explain
select *
from departments_utf8 d, dept_emp de
where d.dept_no = de.dept_no ;

9. rows
MySQL옵티마이저는 각 조건에 대해 가능한 처리 방식의 비용을 비교해 하나의 실행 계획을 수립한다. 이때 비용을 산정하는 방법은 각 처리 방식이 얼마나 많은 레코드를 읽고 비교해야 하는지 예측해 보는 것이다. 대상 테이블에 레코드, 인덱스 분포도를 통계정보를 기준으로 예측한다.
rows 컬럼은 실행 계획의 효율성 판단을 위해 예측했던 레코드 건수를 보여준다. 이는 쿼리를 처리하기 위해 얼마나 많은 레코드를 디스크로부터 일고 체크해야 하는지를 의미한다.
explain
select * from dept_emp where from_date >= '1985-01-01';
*rows:331143 -> SQL 처리를 위해 대략 331,143건의 레코드를 읽어야 할것이라고 예측

explain
select * from dept_emp where from_date >= '2002-07-01';
*rows:292 -> SQL 처리를 위해 대략 292건의 레코드를 읽어야 할것이라고 예측, Date 타입의 key_len은 3바이트

explain
select * from dept_emp where from_date >= '1985-01-01' limit 10;
*풀 테이블 스캔을 사용하면 rows값이 331,143, LIMIT 10 조건을 추가하면 165,571로 반정도 줄었다. LIMIT이 포함되는 쿼리는 rows에 표시되는 값이 오차가 심해서 도움이 되지 않는다.

10. Extra
쿼리의 실행계획에서 성능상 중요한 내용인 자주 표시 된다.
1) const row not found
const 접근 방식으로 테이블을 읽었지만 실제로 해당 테이블에 레코드가 1건도 존재하지 않으면 Extra 컬럼에 이 내용이 표시된다. Extra 컬럼에 이런 메시지가 표시되는 경운에는 테이블에 적절히 테스트용 데이터를 저장하고 실행 계획을 확인해 보는 것이 좋다.
2) DISTINCT
Extra 컬럼에 Distinct 키워드가 표시
departments 테이블과 dept_emp 테이블에 모두 존재하는 dept_no만 중복 없이 유니크하게 가져오기 위한 쿼리이다. 두 테이블을 조인해서 그 결과에 다시 DISTINCT 처리를 넣은 것이다.
쿼리의 DISTINCT를 처리하기 위해 조인하지 않아도 되는 항목은 모두 무시하고 꼭 필요한 것만 조인 했으며, dept_emp 테이블에서 꼭 필요한 레코드만 읽는다.
explain
select distinct d.dept_no
from departments d, dept_emp de where d.dept_no = de.dept_no ;
[DISTINCT 처리 방식]
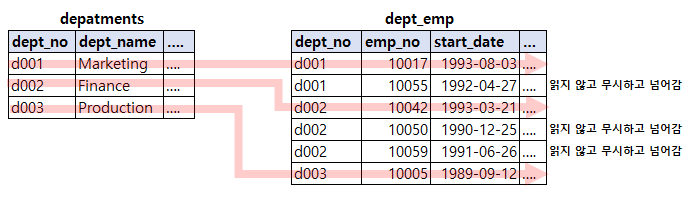
쿼리의 DISTINCT를 처리하기 위해 조인하지 않아도 되는 항목은 모두 무시하고 꼭 필요한 것만 조인, dept_emp 테이블에서는 꼭 필요한 레코드만 읽는다.
3) Full scan on NULL key
"col1 IN (SELECT col2 FROM ...)" col1이 NULL을 만나면 풀 테이블 스캔을 사용할 것이라는 사실을 알려주는 키워드이다. col1이 NULL값이 된다면 "NULL IN (SELECT col2 FROM ...)" 과 같이 바뀐다.SQL 표준에서는 NULL을 알수 없는 값으로 정의하며 NULL에 대한 연산 규칙을 정의하고 있다. 그 정의에 따라 이조건은 다음과 같이 비교 된다.
- 서브 쿼리가 1건이라도 결과 레코드를 가진다면 최종 비교 결과는 NULL
- 서브 쿼리가 1건도 결과 레코드를 가지지 않는다면 최종 비교 결과는 FALSE
이 비교과정에서 col1이 NULL이면 FULL TABLE SCAN을 해야만 결과를 알아낼 수 있다. 하지만, col1이 NOT NULL이라면 해당사항이 없다.
EXPLAIN
SELECT d.dept_no, NULL IN (SELECT id.dept_name FROM departments id)
FROM departments d;
컬럼이 NOT NULL로 정의되지는 않았지만 NULL 비교 규칙을 무시해도 된다면 "col1 IS NOT NULL" 이라는 조건을 지정한다. col1이 NULL이라면 False가 되기 때문에 col1 IN (SELECT col2 FROM ...) 조건을 실행하지 않는다.
explain
select *
from emp e
where mgr is not null
and mgr in (select empno from emp);
"Full scan on NULL key" 코맨트가 실행계획의 Extra 컬럼에 표시 됐다고 하더라도 IN, NOT IN 연산자의 왼쪽에 있는 값이 실제로 NULL이 없다면 풀 테이블 스캔은 발생하지 않는다.
4) Impossible HAVING (MySQL 5.1부터)
HAVING 절의 조건을 만족하는 레코드가 없을 때 실행 계획의 Extra 컬럼에는 "Impossible HAVING" 키워드가 표시된다.
explain
select e.emp_no, count(*) as cnt
from employees e
where e.emp_no=10001
group by e.emp_no
having e.emp_no is null;
e.emp_no 컬럼은 Primary Key 이면서 NOT NULL 컬럼이다. e.emp_no is null 조건을 만족할 수 없으므로 Extra 컬럼에서 "Impossible HAVING"이라는 키워드를 표시한다. 테이블 구조상 불가능한 조건뿐 아니라 실제 데이터 때문에 이런 현상이 발생하기도 하므로 주의해야 한다. 대부분이 쿼리가 제대로 작성되지 못한 경우이므로 쿼리 내용을 다시 점검해야 한다.
5) Impossible WHERE (MySQL 5.1부터)
WHERE 조건이 항상 FALSE가 될 수 밖에 없는 경우 "Impossible WHERE" 가 표시된다.
explain
select * from employees e where e.emp_no is null;
emp_no 컬럼은 NOT NULL 이므로 emp_no is null 조건은 항상 FALSE가 되고 쿼리의 실행 계획에는 "불가능한 WHERE 조건"으로 Extra 컬럼에 출력된다.
6) no matching row in const table (Impossible WHERE noticed after reading const tables)
위의 "Impossible WHERE" 경우 실제 데이터를 읽어보지 않고 바로 테이블 구조상으로 불가능한 조건으로 판단할 수 있다.
explain
select * from employees e where e.emp_no=0;

이 쿼리는 실제로 실행되지 않으면 emp_no = 0 인 레코드가 있는지 없는지 판단할 수 없다. 그런데 이 쿼리의 실행 계획만 확인했을 뿐인데, 옵티마이저는 사번이 0인 사원이 없다는 것까지 확인한 것이다.
이를 토대로 MySQL이 실행 계획을 만드는 과정에서 쿼리의 일부분을 실행해 본다는 사실을 알 수 있다. 또한 이 쿼리는 employees 테이블의 프라이머리 키를 동등 조건으로 비교하고 있다. 이럴 때는 const 접근 방식을 사용한다.
위의 SQL 예제는 MySQL8.0에서 Extra에선 no matching row in const table 로 표시된다. Impossible WHERE noticed after reading const tables 로 표시되는 예제 못 찾았다.
*const 접근방식은 Primary Key or Unique key를 사용하여 반드시 1건을 반환한다.
쿼리에서 const 접근 방식이 필요한 부부은 실행 계획 수립 단계에서 옵티마이저가 직접 쿼리의 일부를 실행하고, 실행된 결과 값을 원본 쿼리의 상수로 대체한다.
select *
from employees oe
where oe.first_name = (select ie.first_name from employees ie where ie.emp_no=10001);
즉, 위와 같은 쿼리를 실행하면 WHERE 조건절의 서브쿼리는(Primary key통한 조회여서 const접근 방식을 사용) 옵티마이저가 실행한 결과를 다음과 같이 대체한 다음, 본격적으로 쿼리를 실행한다.
select *
from employees oe
where oe.first_name = 'Georgi';
explain
select *
from employees oe
where oe.first_name = (select ie.first_name from employees ie where ie.emp_no=10001);
7) No matching min/max row (MySQL 5.1부터)
MIN()이나 MAX()와 같은 집합 함수가 있는 쿼리의 조건절에 일치하는 레코드가 한 건도 없을 때는 Extra 컬럼에 "No matching min/max row"라는 메시지가 출력된다. 그리고 MIN()이나 MAX()의 결과로 NULL이 반환된다.
explain
select min(dept_no), max(dept_no)
from dept_emp
where dept_no = '';
select min(dept_no), max(dept_no)
from dept_emp
where dept_no = '';
* Extra 컬럼에서 출력되는 내용 중에서 "No matching ..." 이나 "Impossible WHERE ..." 등의 메시지는 잘못 생각하면 쿼리 자체가 오류인 것처럼 오해하기 쉽다. 하지만 Extra 컬럼에 출력되는 내용은 단지 쿼리의 실행 계획을 산출하기 위한 기초 자료가 없음을 표현하는 것뿐이다. Extra 컬럼에 이러한 메시지가 표시된다고 해서 실제 쿼리 오류가 발생하는 것은 아니다.
8) no matching row in const table
아래 쿼리와 같이 조인에 사용된 테이블에서 const 방식으로 접근할 때, 일치하는 레코드가 없을 때 표시 된다. 이 메시지 또한 "Impossible WHERE ..."와 같은 종류로 실행 계획을 만들기 위한 기초 자료가 없음을 의미한다.
explain
select *
from dept_emp de,
(select emp_no from employees where emp_no=0) tb1
where tb1.emp_no = de.emp_no
and de.dept_no = 'd005';
9) No tables used (MySQL 5.0의 "No table"에서 키워드 변경됨
FROM 절이 없거나, FROM절에 상수 테이블을 의미하는 DUAL(컬럼과 레코드를 각각 1개씩만 가지는 상수 테이블)이 사용될 때는 Extra 컬럼에 "No tables used"라는 메시지가 표시된다.
explain select 1;
explain select 1 from dual;
10) Not exists
A 테이블에는 존재하지만 B 테이블에는 없는 값을 조회할 때 NOT IN (subquery) 형태나 NOT EXISTS 연산자를 주로 사용한다. 이러한 형태의 조인을 Anti-JOIN 이라고 한다. 똑같이 아우터 조인(LEFT OUTER JOIN)을 이요해도 구현할 수 있다. 일반적으로 ANTI-JOIN으로 처리해야 하지만 레코드 건수가 많을 때는 아우터 조인을 이용하면 빠른 성능을 낼 수 있다.
아우터 조인을 활용해 dept_emp 테이블에는 있지만 departments 테이블에는 없는 dept_no를 조회하는 쿼리를 예제로 살펴보자. departments 테이블을 아우터로 조인해서 ON절이 아닌 WHERE 절의 아우터 테이블(departments)의 dept_no 컬럼이 NULL인 레코드만 체크해서 가져온다. 즉, 안티 조인은 일반 조인(INNER JOIN) 했을 때 나오지 않는 결과만 가져오는 방법이다.
explain
select *
from dept_emp de
left join departments d on de.dept_no = d.dept_no
where d.dept_no is null;
이렇게 아우터 조인을 이용해 안티 조인을 수행하는 쿼리에서는 Extra 컬럼에 Not exists 메시지가 표시된다. Not exists 메시지는 이 쿼리를 NOT EXISTS 형태의 쿼리로 변환해서 처리했음을 의미하는 것이 아니라 MySQL 내부적으로 어떤 최적화를 했는데 그 최적화의 이름이 "Not exists"인 것이다.
11) Range checked for each record (index map : N)
조인 조건에 상수가 없고 둘 다 변수(e1.emp_no, e2.emp_no) 인 경우, MySQL 옵티마이저는 e1 테이블을 먼저 읽고 조인을 위해 e2를 읽을 때, 인덱스 레인지 스캔과 풀 테이블 스캔 중에서 어느 것이 효율적일지 판단할 수 없게 된다. 즉, e1 테이블의 레코드를 하나씩 읽을 때마다 e1.emp_no 값이 계속 바뀌므로 쿼리의 비용 계산을 위한 기준 값이 계속 변하는 것이다. 사번이 1번부터 1억까지 있다고 가정해 보면 e1.emp_no=1인 경우에는 e2 테이블의 1억건 전부를 읽어야 한다. 하지만, e1.emp_no=100000000인 경우에는 e2 테이블 한 건만 읽으면 된다.
"매 레코드마다 어떤 인덱스 레인지 스캔을 할지 체크한다." 고 할 수 있다.
explain
select *
from employees e1, employees e2
where e1.emp_no <= e2.emp_no;
Extra 컬럼에 "Range checked for each record" 가 표시되면 type컬럼에는 ALL로 표시 된다. index map에 표시된 후보 인덱스를 사용할지 여부를 검토해서 후보 인덱스를 안쓰면 풀 테이블 스캔을 사용하여 ALL로 표시된다.
[index map]
CREATE TABLE tb_member(
mem_id INTEGER NOT NULL,
mem_name VARCHAR(100) NOT NULL,
mem_nickname VARCHAR(100) NOT NULL,
mem_region TINYINT,
mem_gender TINYINT,
mem_phone VARCHAR(25),
PRIMARY KEY (mem_id),
INDEX ix_nick_name (mem_nickname, mem_name),
INDEX ix_nick_region (mem_nickname, mem_region),
INDEX ix_nick_gender (mem_nickname, mem_gender),
INDEX ix_nick_phone (mem_nickname, mem_phone)
);index map:0x19 라고 하면 0x19값의 이진 값은 11001이다. Show create table employees 명령으로 테이블 구조를 조회했을때 나열된 인덱스의 순번을 의미한다.

실행 계획에서 index map : 0x19 의 의미는 위의 표에서 각 자리 수의 값이 1인 인덱스를 사용 가능한 인덱스 후보로 선정했음을 의미한다. 각 레코드 단위로 후보 인덱스 중에 어떤 인덱스를 사용할지 결정 하는데 비트맵의 자리 수가 1인 순번의 인덱스가 대상이다.
*실행 계획의 Extra 컬럼에 "Range checked for each record"가 표시되는 쿼리가 많이 실행되는 MySQL 서버에서는 "SHOW GLOBAL STATUS" 명령으로 표시되는 상태 값 중에서 "Select_range_check"의 값이 크게 나타난다.
12) Scanned N databases (MySQL 5.1부터)
MySQL5.0부터 제공되는 INFORMATION_SCHEMA DB는 MySQL 서버 내에 존재하는 DB의 메타 정보(테이블, 컬럼, 인덱스 등의 스키마 정보) 를 모아두고 읽기 전용이며 실제로 테이블에 레코드가 있는 것이 아니라 조회시 메타 정보를 MySQL 서버의 메모리에서 가져와서 보여준다. 그래서 많은 테이블을 조회할 경우 시간이 걸린다.
MySQL5.1 부터는 INFOMATION_SCHEMA DB의 조회 성능이 개선 되었고 Extra 컬럼에 "Scanned N databases"라는 메시지가 표시된다. 여기서 N의 의미는 아래와 같다.
- 0 : 특정 테이블의 정보만 요청되어 데이터베이스 전체의 메타 정보를 읽지 않음
ex) employees DB의 employees 테이블 정보만 읽는 경우 "Scanned 0 databases" 표시
- 1 : 특정 데이터베이스내의 모든 스키마 정보가 요청되어 해당 데이터베이스의 모든 스키마 정보를 읽음
- ALL : MySQL 서버 내의 모든 스키마 정보를 다 읽음
explain
select table_name
from information_schema.tables
where table_schema = 'employees' and table_name = 'employees';
실제 실행계획은 "Scanned 0 databases"라고 표시 되지 않는다.
13) Select tables optimized away
MIN(), MAX()만 SELECT 절에 사용되어 인덱스를 오름차순 또는 내림차순으로 1건만 읽는 형태의 최적화가 적용된다면 Extra 컬럼에 표시된다.
* dept_emp 테이블의 INDEX 정보
PRIMARY : dept_no+emp_no, ix_empno_fromdate : emp_no + from_date
explain
select max(emp_no), min(emp_no) from dept_emp ;
explain
select max(emp_no), min(emp_no) from dept_emp where dept_no = 'd001' group by dept_no ;
GROUP BY를 사용하면 최적화를 하지 못한다. WHERE 절에 dept_no= 'd001' 조건을 적용해도 마찬가지 이다.
* salaries 테이블의 INDEX 정보
PRIMARY : emp_no + from_date, ix_salary : salary
explain
select max(from_date), min(from_date) from salaries where emp_no = 10001;
min, max 함수 사용시 조건절을 사용할 때 그에 맞는 적절한 인덱스가 있다면 최적화가 가능하다.
explain
select max(salary), min(salary) from salaries where emp_no = 10001;
emp_no + salary 로 구성된 인덱스가 없어서 최적화가 불가능 하다.
MyISAM 테이블은 전체 레코드 건수를 별도로 관리 하기 때문에 인덱스나 데이터를 읽기 않고도 전체 건수를 조회 한다.
[MyISAM 테이블 : employee_name]
explain
select count(*) from employee_name;
14) Skip_open_table, Open_frm_only, Open_trigger_only, Open_full_table (MySQL 5.1부터)
INFORMATION_SCHEMA DB의 메타 정보를 조회하는 SELECT 쿼리에서만 표시되는 내용이다. 테이블의 메타 정보가 저장된 파일(*.FRM)과 트리거가 저장된 파일(*.TRG) 또는 데이터 파일 중에서 필요한 파일만 읽었는지 또는 불가피하게 모든 파일을 다 읽었는지 등의 정보를 보여준다. Extra 컬럼에 표시되는 4가지 메시지를 살펴보자.
- Skip_open_table : 테이블의 메타 정보가 저장된 파일을 별도로 읽을 필요가 없음
- Open_frm_only : 테이블의 메타 정보가 저장된 파일(*.FRM)만 열어서 읽음
- Open_trigger_only : 트리거 정보가 저장된 파일(*.TRG)만 열어서 읽음
- Open_full_table : 최적화되지 못해서 테이블 메타 정보 파일(*.FRM)과 데이터(*.MYD) 및 인덱스 파일(*.MYI)까지 모두 읽음
위의 내용에서 데이터(*.FRM)파일이나 인덱스(*.MYI)에 관련된 내용은 MyISAM(마이아이삼)에만 해당하며, InnoDB 스토리지 엔진을 사용하는 테이블에는 적용되지 않는다.
[ 테이블 위치 ]
show variables like 'datadir' ;
employees.ibd (IBD 파일: INNO DB 각 테이블당 데이터가 저장되는 파일)
salaries_part1 파티션의 경우 아래와 같이 저장됨.
employee_name.MYD (MyISAM Data파일)
employee_name.MYI (MyISAM Index파일)
perfomance_schema 파일은 SDI파일로 저장된다.
[데이터베이스 내 각각의 테이블을 IBD파일로 저장여부]
show variables like 'innodb_file_per_table';
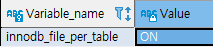
'innodb_file_per_table' 값이 OFF(0) 이면 ibdata1(시스템 테이블스페이스)에 저장한다.
디스크 스토리지 영역(Filesystem) 중에 테이블스페이스는 유저테이블 스페이스(IBD)와 시스템테이블 스페이스(ibdata1)로 구분할 수 있다. 유저테이블스페이스에는 인덱스파일과 데이터 파일이 저장되고, 시스템테이블스페이스에는 dictionary 및 undo등이 저장된다.
[Filesystem(디스크스토리지영역) 구성내역]
ibdata1(system table space) : insert buffer, innodb dictionary, double write buffer, rollback segment, undo space
ibd(user table space) : primary key, data, secondary indexes
ib_log(Redo Logs) : ib_logfile0, ib_logfile1
table1.frm
15) unique row not found (MySQL 5.1부터)
두 개의 테이블이 각각 Unique(PK포함) 컬럼으로 아우터 조인을 수행하는 쿼리에서 아우터 테이블에 일치하는 레코드가 존재하지 않을 때 Extra 컬럼에 표시된다.
create table test1(col1 int, col2 int, primary key(col1));
create table test2(col1 int, col2 int, primary key(col1));
insert into test1 values (1,1), (2,2);
insert into test2 values (1,1) ;
explain
select *
from test1 t1
left join test2 t2 on t1.col1 = t2.col1
where t1.col1 = 2;

16) Using filesort
order by 처리가 인덱스를 사용하지 못할 때만 실행 계획의 Extra 컬럼에는 "Using filesort" 코멘트가 표시된다.
MySQL 옵티마이저는 레코드를 읽어서 소트 버퍼(sort buffer)에 복사해 퀵 소트 알고리즘을 수행하여 정렬결과를 클라이언트에 보낸다.
[employees index : PRIMARY(emp_no), ix_first_name(first_name), ix_hiredate(hire_date)]
explain
select * from employees order by last_name desc;

실행 계획의 Extra 컬럼에 "Using filesort" 가 출력되는 쿼리는 부하가 발생하므로 쿼리를 튜닝하거나 정렬에 사용할 수 있는 인덱스를 생성하여 부하를 줄여 준다.
17) Using index (커버링 인덱스)
데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 쿼리를 처리할 수 있을 때 Extra 컬럼에 "Using index"가 표시된다. 인덱스를 이용해 처리하는 쿼리에서 가장 큰 부하를 차지하는 부분은 인덱스를 검색해 일치하는 레코드의 주소값(rowid or Innodb : PK)을 이용해 데이터 파일의 레코드값을 가져오는 작업이다. 최악의 경우는 레코드 한 건 마다 디스크를 한번씩 읽어야 할 수도 있다.
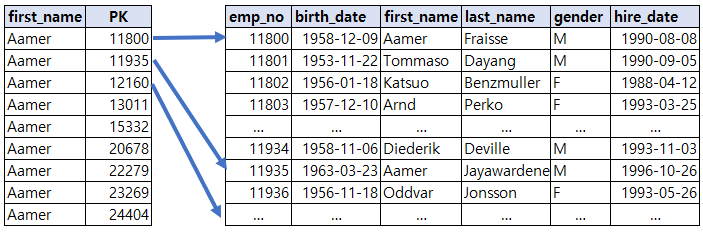
explain
select first_name from employees where first_name = 'Aamer' ;
위 쿼리는 first_name 컬럼이 있는 ix_first_name 인덱스만 읽고 처리를 하여 Extra컬럼에 "Using index"라는 메시지가 출력된다. 인덱스만으로 처리되는 것을 커버링 인덱스(Covering index)라고 한다.
explain
select emp_no, first_name from employees where first_name = 'Aamer' ;
InnoDB 테이블의 보조 인덱스는 데이터 레코드의 주소 값으로 Primary Key를 사용한다. first_name만으로 인덱스를 만들어도 emp_no컬럼이 같이 저장되는 클러스터링 인덱스 특성 때문에 위 쿼리가 커버링 인덱스로 처리 된다.
* Extra 컬럼에 표시되는 "Using index"와 접근 방법(type컬럼)의 "index"를 자주 혼동할 때가 있는데 성능상 반대되는 개념이라서 반드시 구분해서 이해하자. "Using index"는 커버링 인덱스가 사용되어 인덱스만 읽고 쿼리를 처리하는 방식이고 type컬럼에 표시되는 "index"는 인덱스 풀 스캔으로 처리하는 방식이다.
18) Using index for group-by
Group by 처리를 위해 MySQL서버는 그룹핑 기준 컬럼을 이용해 정렬 작업을 수행하고 다시 정렬된 결과를 그룹핑하는 형태의 고부하 작업을 필요로 한다. 하지만 group by 처리가 인덱스(B-Tree 인덱스만)를 이용하면 정렬된 인덱스 컬럼을 순서대로 읽으면서 그룹핑 작업만 수행한다. Group by 처리가 인덱스를 이용할 때 쿼리의 실행 계획에서는 Extra 컬럼에 "Using index for group-by" 메시지가 표시된다. 이를 "루스 인덱스 스캔" 이라고도 한다.
[루스 인덱스 스캔]
Group by 처리를 위해 단순히 인덱스를 순서대로 쭉 읽는 타이트 인덱스 스캔과는 달리 루스 인덱스 스캔은 인덱스에서 필요한 부분만 듬성 듬성 읽는다.
explain
select dept_no, min(emp_no), max(emp_no)
from dept_emp
group by dept_no;
explain
select dept_no, min(emp_no),max(emp_no)
from dept_emp
where dept_no between 'd002' and 'd004'
group by dept_no;
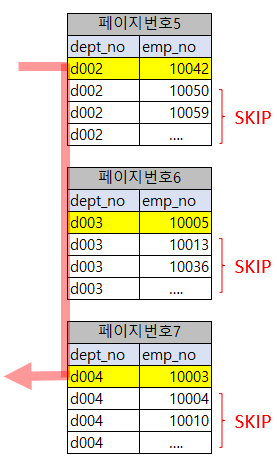
[타이트 인덱스 스캔(인덱스 스캔)을 통한 GROUP BY 처리]
인덱스를 이용해 GROUP BY 절을 처리할 수 있더라도 AVG()나 SUM() 또는 COUNT(*)와 같이 조회하려는 값이 모든 인덱스를 다 읽어야 할 때는 필요한 레코드만 듬성 듬성 읽을 수가 없다. 이런 쿼리는 단순히 GROUP BY를 위해 인덱스를 사용하기는 하지만 이를 루스 인덱스 스캔이라고 하지는 않는다.
explain
select dept_no, count(*) from dept_emp group by dept_no;
GROUP BY에서 인덱스를 사용하려면 GROUP BY 조건의 인덱스 사용 요건이 갖춰줘야 한다.
# WHERE 절에 조건이 없는 경우
Where 절의 조건이 전혀 없는 쿼리는 GROUP BY에 쓰인 컬럼과 MIN, MAX로 조회하는 컬럼이 인덱스가 있으면 루스 인덱스 스캔을 사용한다. 그렇지 못한 쿼리는 타이트 인덱스 스캔(인덱스 스캔)이나 별도의 정렬 과정을 통해 처리 된다.
[employees index : PRIMARY(emp_no), ix_first_name(first_name), ix_hiredate(hire_date)]
explain select dept_no from dept_emp group by dept_no;
explain select dept_no, min(emp_no) from dept_emp group by dept_no;
#WHERE 조건절이 있지만 검색을 위해 인덱스를 사용하지 못하는 경우
GROUP BY절은 인덱스를 사용할 수 있지만 WHERE 조건절이 인덱스를 사용하지 못할 때는 먼저 GROUP BY를 위해 인덱스를 읽은 후, WHERE 조건의 비교를 위해 데이터 레코드를 읽어야만 한다. 타이트 인덱스 스캔(인덱스 스캔) 과정을 통해 GROUP BY가 처리된다.
explain select dept_no, min(emp_no) from dept_emp where to_date = '9999-01-01' group by dept_no;
#WHRER 절에 조건이 있지만 검색을 위해 인덱스를 사용하는 경우
조건절에 사용된 인덱스를 GROUP BY 처리가 다시 사용할 수 있을 때만 루스 인덱스 스캔을 사용할 수 있다. 만약 WHERE 조건절이 사용할 수 있는 인덱스와 GROUP BY가 사용할 수 있는 인덱스가 다른 경우라면 옵티마이저는 WHERE 조건절이 인덱스를 사용하도록 실행 계획을 수립하는 경향이 있다.
explain
select dept_no, min(emp_no),max(emp_no)
from dept_emp
where dept_no between 'd002' and 'd004'
group by dept_no;
*루스 인덱스 스캔의 손익분기점
WHERE 절의 조건이 검색을 위해 인덱스를 이용하고 GROUP BY가 같은 인덱스를 사용할 수 있는 쿼리라 하더라도 인덱스 루스 스캔을 사용하지 않을 수 있다. 즉, WHERE 조건에 의해 검색된 레코드 건수가 적으면 루스 인덱스 스캔을 사용하지 않아도 매우 빠르게 처리될 수 있기 때문이다. 루스 인덱스 스캔은 주로 대량의 레코드를 GROUP BY 하는 경우 성능 향상 효과가 있을 수 있기 때문에 옵티마이저가 손익 분기점을 판단한다.
다음 예제에서 WHERE 절의 검색 범위를 더 좁히면 Extra 컬럼에서 "Using index for group-by" 처리가 사라진 것을 확인할 수 있다.
explain
select emp_no
from salaries where emp_no between 10001 and 10099
group by emp_no;
explain
select emp_no
from salaries -- where emp_no between 10001 and 10099
group by emp_no;
19) Using join buffer (MySQL 5.1부터)
MySQL 옵티마이저는 조인되는 두 테이블에 있는 각 컬럼에서 인덱스를 조사하여 인덱스가 없는 테이블이 있으면 그 테이블을 먼저 읽어서 조인을 실행한다. 뒤에 읽는 테이블은 검색 위주로 사용되기 때문에 인덱스가 없으면 성능에 큰 악영향을 미친다. 드리븐 테이블에 검색을 위한 적절한 인덱스가 없으면 드라이빙 테이블로부터 읽은 레코드의 건수만큼 매번 드리븐 테이블을 풀 테이블 스캔이나 인덱스 풀 스캔해야 할것이다. 이때 드리븐 테이블의 비효율적인 검색을 보안하기 위해 드라이빙 테이블에서 읽은 레코드를 조인버퍼에 임시로 보관한다. 조인버퍼가 사용되면 Extra 컬럼에 "Using join buffer"란느 메시지가 표시된다.
조인버퍼는 join_buffer_size라는 시스템 설정 변수에 최대 사용 가능한 버퍼 크기를 설정할 수 있다. 온라인 웹 서비스용 서버라면 1MB정도로 충분하다. 아래 쿼리는 조인 조건이 없는 카테시안 조인을 수행하는 쿼리로 조인 버퍼를 사용한다.
explain
select *
from dept_emp de, employees e
where de.from_date > '2005-01-01' and e.emp_no < 10900;
[조인버퍼 사이즈]
show variables like 'join_buffer_size';
select 262144/1024/1024; --0.25
20) Using sort_union(...), Using union(...), Using intersect(...)
Index_merge 접근 방식(type='index_merge')로 실행되는 경우에 Extra 컬럼에 두 인덱스를 읽은 결과를 어떻게 병합했는지 설명하기 위해 아래 3개의 메시지중에 하나를 출력한다.
- Using intersect(...)
각각의 인덱스를 사용할 수 있는 조건이 AND로 연결된 경우 각 처리 결과의 교집합을 추출하는 작업을 수행
- Using union(...)
각 인덱스를 사용할 수 있는 조건이 OR로 연결된 경우 각 처리 결과의 합집합을 추출하는 작업을 수행
- Using sort_union(...)
Using union과 같은 작업을 수행하지만 Using union으로 처리될 수 없는 경우(OR로 연결된 상대적으로
대량의 range 조건들) 이 방식으로 처리. Using sort_union은 PK만 먼저 읽어서 졍렬하고 병합한 후에
레코드를 읽어서 반환한다.
실제로는 레코드 건수에 거의 관계없이 조건절에 사용된 비교 조건이 동등 조건이면 Using union()이 사용되며, 그렇지 않으면 Using sort_union() 이 사용된다. Using union은 싱글 패스 정렬 알고리즘을 사용하면 Using sort_union은 투 패스 정렬 알고리즘을 사용한다.
21) Using temporary
쿼리를 처리하는 동안 중간 결과를 저장하기 위해 임시 테이블(Temporary table)을 사용한다. 임시 테이블은 메모리상에 생성될 수도 있고 디스크상에 생성될 수도 있다. Extra 컬럼에 "Using temporary"로 표시되며 임시 테이블이 메모리에 생성되었는지 디스크에 생성되었는지는 PLAN만으로 알 수 없다.
아래의 쿼리는 GROUP BY 컬럼과 ORDER BY 컬럼이 다르기 때문에 임시 테이블이 필요한 작업이다. 인덱스를 사용하지 못하는 GROUP BY 쿼리는 실행 계획에서 "Using temporary" 메시지가 표시되는 대표적인 형태의 쿼리다.
explain
select * from employees group by gender order by emp_no;
실행계획에 Extra 컬럼에 "Using temporary"가 표시되지 않지만 내부적으로 임시 테이블을 사용 할 때도 많다. 대표적으로 메모리나 디스크에 임시 테이블을 생성하는 쿼리는 다음과 같다.
- FROM절에 사용된 서브 쿼리는 무조건 임시 테이블을 생성한다. 이 테이블을 파생 테이블(Derived table)이라고 부르긴 하지만 결국 실체는 임시 테이블 이다.
- COUNT(DISTINCT column) 를 포함하는 쿼리도 인덱스를 사용할 수 없는 경우에는 임시 테이블이 만들어 진다.
- UNION이나 UNION ALL이 사용된 쿼리도 항상 임시 테이블을 사용해서 결과를 병합한다.
- 인덱스를 사용하지 못하는 정렬 작업 또한 임시 버퍼 공간을 사용하는데 정렬해야 할 레코드가 많아지면 디스크를 사용한다. 정렬에 사용되는 버퍼도 실체는 임시 테이블과 같다. 쿼리가 정렬을 수행할 때는 실행 계획의 Extra 컬럼에 "Using filesort"라고 표시된다.
임시테이블이나 버퍼가 메모리에 저장됐는지 디스크에 저장됐는지는 MySQL 서버의 상태 변수 값으로 확인할 수 있다.
22) Using where
MySQL은 내부적으로 크게 MySQL엔진과 스토리지 엔진이라는 두 개의 레이어로 나눠서 볼 수 있다. 각 스토리지 엔진은 디스크나 메모리상에서 필요한 레코드를 읽거나 저장하는 역할을 하며, MySQL엔진은 스토리지 엔진으로부터 받은 레코드를 가공 또는 연산하는 작업을 수행한다. MySQL 엔진 레이어에서 별도의 가공을 해서 필터링 작업을 처리한 경우에만 Extra 컬럼에 "Using where" 코멘트가 표시된다.
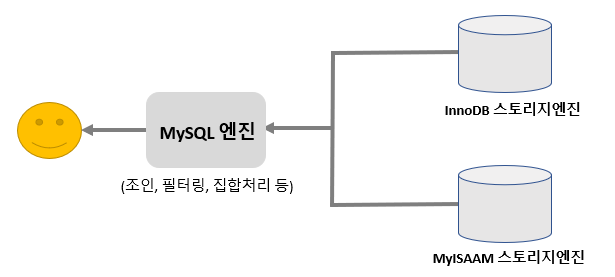
각 스토리지 엔진에서 100건의 레코드를 읽었는데 MySQL 엔진에서 필터링이나 가공 없이 그대로 클라이언트로 전달하면 "Using where"가 표시되지 않느다. 작업 범위 제한 조건은 각 스토리지 엔진 레벨에서 처리되지만 체크 조건은 MySQL 엔진 레이어에서 처리된다.
explain
select * from employees where emp_no between 10001 and 10100 and gender = 'F';
위 쿼리에서 작업 범위 제한 조건은 "emp_no between 10001 and 10100"이며 "gender='F'" 는 체크 조건이다. 스토리지엔진은 100건의 데이터를 읽어서 MySQL엔진에 넘겨주고 MySQL엔진은 63건의 레코드를 필터링해서 37건을 클라이언트에게 전송한다. 여기서 filtered 컬럼의 값이 100 미만이라면 체크조건을 실행하여 필터링 했다는 의미로 볼 수 있다.(MySQL 엔진에 의해 필터링되고 50프로만 남았다)
MySQL엔진과 스토리지 엔진은 이원화된 구조이다. WHERE category=10 and name like '%abc%' 에서 category조건을 만족하는 레코드가 100건, name 조건을 만족하는 레코드가 10건이라면 MySQL엔진은 10건의 레코드를 위해 그 10배의 작업을 스토리지 엔진에 요청한다. InnoDB나 MyISAM과 같은 스토리지 엔진과 MySQL엔진은 모두 하나의 프로세스로 동작하기 때문에 성능에 미치는 영향이 작다. 하지만, 스토리지 엔진이 MySQL 엔진 외부에서 작동하는 NDB클러스터는 네트워크 전송 부하까지 겹치기 때문에 성능에 미치는 영향이 큰 편이다.
MySQL 5.1의 InnoDB 플러그인 버전부터는 이원화된 구조의 불합리를 제거하기 위해 WHERE절의 범위 제한 조건 뿐만 아니라 체크 조건까지 모두 스토리지 엔진으로 전달된다. 스토리지 엔진에서는 그 조건에 정확히 일치하는 레코드만 읽고 MySQL 엔진으로 전달하기 때문에 비효율이 사라진다. 위의 예제에서 스토리지 엔진이 꼭 필요한 10건의 레코드만 읽게 된다. MySQL에서 이런 기능을 "Condition push down"이라고 표현한다.
23) Using where with pushed condition
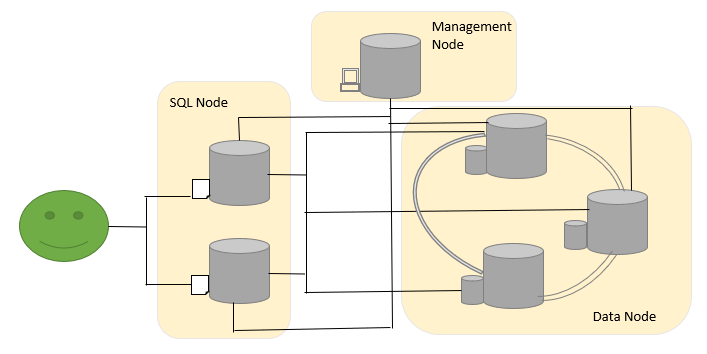
실행계획의 Extra 컬럼에 표시되는 "Using where with pushed condition" 메시지는 "Condition push down"이 적용됐음을 의미하는 메시지다. MySQL 5.1부터는 "Condition push down"이 InnoDB나 MyISAM 스토리지 엔진에도 도입되어 각 스토리지 엔진의 비효율이 상당히 개선됐다고 볼 수 있다.
하지만 MyISAM이나 InnoDB 스토리지 엔진을 사용하는 테이블의 실행 계획에는 "Using where with pushed condition" 메시지가 표시되지 않는다. 이 메시지는 NDB 클러스터 스토리지 엔진을 사용하는 테이블에서만 표시되는 메시지다. NDB 클러스터는 MySQL 엔진의 외부에서 작동하는 스토리지 엔진이라서 스토리지 엔진으로부터 읽은 레코드는 네트워크를 통해 MySQL 엔진으로 전달된다. NDB 클러스틑 여러 개의 노드로 구성되는데 "SQL 노드"는 MySQL 엔진 역할을 담당하며, "데이터 노드"는 스토리지 엔진 역할을 담당한다. 그리고 데이터 노드와 SQL 노드는 네트워크를 통해 TCP/IP 통신을 한다. 그래서 실제 "Condition push down"이 사용되지 못하면 상당한 성능 저하가 발생할 수 있다.
11. EXPLAIN EXTENDED(Filtered 컬럼)
MySQL 5.1.12 버전부터는 필터링이 얼마나 효율적으로 실행됐는지를 사용자에게 알려주기 위해 실행 계획에 Filltered라는 컬럼이 새로 추가됐다. 실행계획에서 Filtered 컬럼을 함계 조회하려면 Explain 명령 뒤에 EXTENDED 라는 키워드를 지정하면 된다. MySQL 8.0 에서는 extended 키워드를 사용하면 SQL Error [1064] [42000]: You have an error in your SQL syntax; 오류가 난다. explain만 사용해도 filtered가 표시된다.
explain
select *
from employees
where emp_no between 10001 and 10100 and gender = 'F';
filtered 컬럼에는 MySQL 엔진에 의해 필터링되어 제거된 레코드는 제외하고 최종적으로 레코드가 얼마나 남았는지의 비율(Percentage)이 표시된다. 스토리지 엔진이 전체 100건(rows=100)의 레코드를 읽어서 MySQL엔진에 전달 했는데 MySQL 엔진에 의해 필터링되고 50%만 남았다는 것을 의미한다. (50건=100건*1/2)
filtered 컬럼의 정보 또한 실제 값이 아니라 통계 정보로부터 예측된 값일 뿐이다. 아래 그림은 위의 쿼리가 실행되면서 스토리지 엔진과 MySQL 엔진에서 얼마나 레코드가 읽히고 버려졌는지를 표현한 것이다.
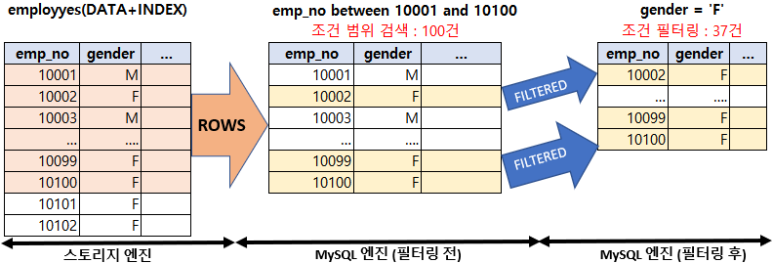
[rows와 filtered 컬럼의 의미]
12. EXPLAIN EXTENDED(추가 옵티마이저 정보)
MySQL 엔진에서 쿼리의 실행 계획을 산출하기 위해 쿼리 문장을 분석해 파스 트리를 생성한다. 또한 일부 최적화 작업에도 이 파스 트리를 이용해 수행한다. "EXPLAIN EXTENED" 명령어의 또 다른 기능은 분석된 파스 트리를 재조합해서 쿼리 문장과 비슷한 순서대로 나열해서 보여주는 것이다.(MySQL8.0에선 explain만 사용)
explain
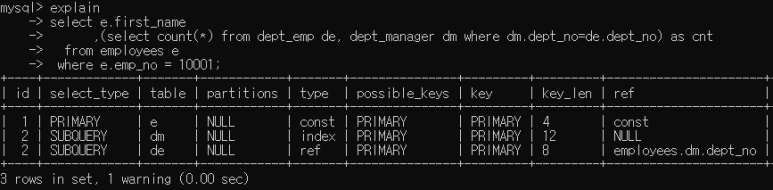
show warnings; (cmd 창에서만 작동)


/* select#1 */
select 'Georgi' AS `first_name`
, (
/* select#2 */
select count(0)
from `employees`.`dept_emp` `de` join `employees`.`dept_manager` `dm`
where (`employees`.`de`.`dept_no` = `employees`.`dm`.`dept_no`)) AS `cnt`
from `employees`.`employees` `e`
where trueexplain 명령어 실행 후에 바로 "show warnings" 명령을 실행하면 옵티마이저가 분석해서 다시 재조합한 쿼리 문장을 확인 할 수 있다. 위의 예제에서는 count(*)가 내부적으로는 count(0)으로 변환되어 처리 되었고 emp_no=10001 조건을 옵티마이저가 미리 실행해서 상수화된 값으로 'Georgi' 가 사용됐다는 것을 알 수 있다.
show warnigs 명령을 이용해서 옵티마이저가 어떻게 쿼리해석, 쿼리변환, 특수한 처리를 수행 했는지를 판단할 수 있다.
13. EXPLAIN PARTITIONS(Partitions 컬럼)
EXPLAIN 에서 partitions 컬럼은 테이블의 파티션 중에서 어떤 파티션을 사용 했는지 표시 된다. 아래 쿼리에서 조회하려는 데이터는 p2001파티션에 저장되어 있다. 옵티마이저는 이 쿼리를 처리하기 위해서 p2001 파티션만 접근하도록 실행 계획을 수립한다. 쿼리를 수행하기 위해 접근 해야할 테이블만 골라내는 과정을 파티션 프루닝(Partition Pruning)이라고 한다.
-- Partition Table 생성
drop table salaries_part1;
CREATE TABLE salaries_part1 (
emp_no INT NOT NULL,
salary INT NOT NULL,
from_date DATE NOT NULL,
to_date DATE NOT NULL,
KEY (emp_no),
# FOREIGN KEY (emp_no) REFERENCES employees (emp_no) ON DELETE CASCADE,
PRIMARY KEY (emp_no, from_date)
)
partition by range columns(from_date)
(
partition p1985 values less than ('1986-01-01'),
partition p1986 values less than ('1987-01-01'),
partition p1987 values less than ('1988-01-01'),
partition p1988 values less than ('1989-01-01'),
partition p1989 values less than ('1990-01-01'),
partition p1990 values less than ('1991-01-01'),
partition p1991 values less than ('1992-01-01'),
partition p1992 values less than ('1993-01-01'),
partition p1993 values less than ('1994-01-01'),
partition p1994 values less than ('1995-01-01'),
partition p1995 values less than ('1996-01-01'),
partition p1996 values less than ('1997-01-01'),
partition p1997 values less than ('1998-01-01'),
partition p1998 values less than ('1999-01-01'),
partition p1999 values less than ('2000-01-01'),
partition p2000 values less than ('2001-01-01'),
partition p2001 values less than ('2002-01-01'),
partition p2002 values less than ('2003-01-01'),
partition p9999 values less than (MAXVALUE)
);
-- DDL 확인
show create table salaries_part1;
-- 데이터 삽입
insert into salaries_part1 select * from salaries;
commit;
-- 건수 확인
select count(*) cnt from salaries
union all
select count(*) cnt from salaries_part1;
explain
select * from salaries_part1
where from_date between '2001-01-01' and '2001-12-31'
*TO_DAYS 함수 : 주어진 날짜를 0000년부터의 일수로 바꾼다
select to_days('2021-01-01'), to_days('2021-01-00') ;
TO_DAYS 함수는 입력된 날짜 값의 포맷이 잘못돼 있다면 NULL을 반환할 수도 있다. 이렇게 MySQL의 파티션 키가 TO_DAYS()와 같이 NULL을 반환할 수 있는 함수를 사용할 때는 쿼리의 실행 계획에서 partitions 컬럼의 테이블의 첫 번째 파티션에 포함되기도 한다. range 파티션을 사용하는 테이블에서 NULL은 항상 첫 번째 파티션에 저장되기 때문에 실행 계획의 partitions 컬럼에 첫 번째 파티션도 함께 포함된다. 하지만 실제 필요한 파티션과 테이블의 첫 번째 파티션이 함께 partitions 컬럼에 표시된다 하더라도 성능 이슈는 없다.
* 파티션 프루닝이 가능한 함수 YEAR, TO_DAYS
데이터 컬럼을 조작해야 한다면 데이터를 정수형으로 반환하고 파티션 프루닝이 가능한 year함수와 to_days 함수만을 사용해야 한다.
[파티션 : YEAR]
CREATE TABLE salaries_party (
emp_no INT NOT NULL,
salary INT NOT NULL,
from_date DATE NOT NULL,
to_date DATE NOT NULL,
KEY (emp_no),
PRIMARY KEY (emp_no, from_date)
)
partition by range (year(from_date))
(
partition p1985 values less than (1986),
partition p1986 values less than (1987),
partition p1987 values less than (1988),
partition p1988 values less than (1989),
partition p1989 values less than (1990),
partition p1990 values less than (1991),
partition p1991 values less than (1992),
partition p1992 values less than (1993),
partition p1993 values less than (1994),
partition p1994 values less than (1995),
partition p1995 values less than (1996),
partition p1996 values less than (1997),
partition p1997 values less than (1998),
partition p1998 values less than (1999),
partition p1999 values less than (2000),
partition p2000 values less than (2001),
partition p2001 values less than (2002),
partition p2002 values less than (2003),
partition p9999 values less than (MAXVALUE)
);
insert into salaries_party select * from salaries;
commit;
explain
select * from salaries_party
where from_date between '2001-01-01' and '2001-12-31';
[파티션 : TO_DAYS]
CREATE TABLE salaries_partd (
emp_no INT NOT NULL,
salary INT NOT NULL,
from_date DATE NOT NULL,
to_date DATE NOT NULL,
KEY (emp_no),
PRIMARY KEY (emp_no, from_date)
)
partition by range (to_days(from_date))
(
partition p1985 values less than (to_days('1986-01-01')),
partition p1986 values less than (to_days('1987-01-01')),
partition p1987 values less than (to_days('1988-01-01')),
partition p1988 values less than (to_days('1989-01-01')),
partition p1989 values less than (to_days('1990-01-01')),
partition p1990 values less than (to_days('1991-01-01')),
partition p1991 values less than (to_days('1992-01-01')),
partition p1992 values less than (to_days('1993-01-01')),
partition p1993 values less than (to_days('1994-01-01')),
partition p1994 values less than (to_days('1995-01-01')),
partition p1995 values less than (to_days('1996-01-01')),
partition p1996 values less than (to_days('1997-01-01')),
partition p1997 values less than (to_days('1998-01-01')),
partition p1998 values less than (to_days('1999-01-01')),
partition p1999 values less than (to_days('2000-01-01')),
partition p2000 values less than (to_days('2001-01-01')),
partition p2001 values less than (to_days('2002-01-01')),
partition p2002 values less than (to_days('2003-01-01')),
partition p9999 values less than (MAXVALUE)
);
show create table salaries_partd;
CREATE TABLE `salaries_partd` (
`emp_no` int NOT NULL,
`salary` int NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`),
KEY `emp_no` (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
/*!50100 PARTITION BY RANGE (to_days(`from_date`))
(PARTITION p1985 VALUES LESS THAN (725372) ENGINE = InnoDB,
PARTITION p1986 VALUES LESS THAN (725737) ENGINE = InnoDB,
PARTITION p1987 VALUES LESS THAN (726102) ENGINE = InnoDB,
PARTITION p1988 VALUES LESS THAN (726468) ENGINE = InnoDB,
PARTITION p1989 VALUES LESS THAN (726833) ENGINE = InnoDB,
PARTITION p1990 VALUES LESS THAN (727198) ENGINE = InnoDB,
PARTITION p1991 VALUES LESS THAN (727563) ENGINE = InnoDB,
PARTITION p1992 VALUES LESS THAN (727929) ENGINE = InnoDB,
PARTITION p1993 VALUES LESS THAN (728294) ENGINE = InnoDB,
PARTITION p1994 VALUES LESS THAN (728659) ENGINE = InnoDB,
PARTITION p1995 VALUES LESS THAN (729024) ENGINE = InnoDB,
PARTITION p1996 VALUES LESS THAN (729390) ENGINE = InnoDB,
PARTITION p1997 VALUES LESS THAN (729755) ENGINE = InnoDB,
PARTITION p1998 VALUES LESS THAN (730120) ENGINE = InnoDB,
PARTITION p1999 VALUES LESS THAN (730485) ENGINE = InnoDB,
PARTITION p2000 VALUES LESS THAN (730851) ENGINE = InnoDB,
PARTITION p2001 VALUES LESS THAN (731216) ENGINE = InnoDB,
PARTITION p2002 VALUES LESS THAN (731581) ENGINE = InnoDB,
PARTITION p9999 VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */
insert into salaries_partd select * from salaries;
commit;
explain
select * from salaries_partd
where from_date between '2001-01-01' and '2001-12-31';
-- p1985에 NULL 데이터 없다.
select * from salaries_partd partition(p1985) where from_date is null ;
-- 테이블 salaries_partd의 총 건수 : 2844047
select count(*) from salaries_partd ;
-- partition p2001 건수 : 247652
select count(*) from salaries_partd partition(p2001);
-- 247652 ÷ 2844047 * 100 = 8.7%
select (select count(*) from salaries_partd partition(p2001))/(select count(*) from salaries_partd);
'MySQL > MySQL' 카테고리의 다른 글
| 실행계획 분석시 주의 사항 (0) | 2024.12.06 |
|---|---|
| MySQL 실행계획(Extra) (0) | 2024.12.06 |
| RealMySQL 예제 데이터 (0) | 2024.12.06 |
| 해시알고리즘, 해시인덱스 (0) | 2024.12.06 |
| INDEX 엑세스 조건 (0) | 2024.12.06 |